Share
Containers have become a staple of the enterprise IT landscape, and now there’s definitive research that shows just how large scale that adoption has been. According to 451 Research, in its recently published The State of Data Management in the Container Era research, more than half of today’s organizations are actively using containers, with many more on the way. But with that rise comes a challenge: how to manage container and Kubernetes storage demands.
In this article we review the key container management insights of this report, which is based on conversations with industry players and end users, several 451 Research analysts, and a number of recent 451 Research Voice of the Enterprise (VotE) surveys.
What the Numbers Say
The 451 Research report The State of Data Management in the Container Era (August 2020) opens by establishing the widespread adoption of cloud-native technology—containers, service meshes, microservices, and serverless functions. As shown in Figure 1, more than half (55%) of organizations are actively using containers while another 18% are in the discovery stage. And Kubernetes is a container management platform in use by 42%.
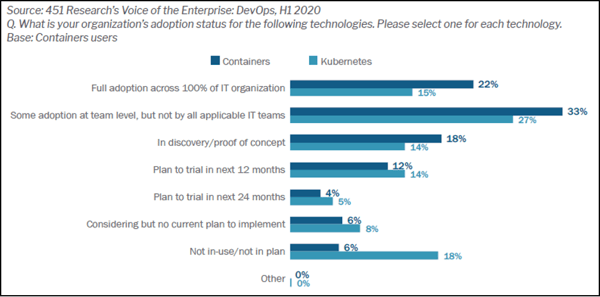 Figure 1: Container and Kubernetes Adoption Status
Figure 1: Container and Kubernetes Adoption Status
Furthermore, 56% of the companies running containers are using half or more of them to run stateful applications. These stateful containerized applications introduce challenges related to data persistence and storage. They also have to be adequately protected by the company’s data protection policies. Last but not least, data management for stateful containerized applications must take into account today’s distributed hybrid and multicloud environments.
Let’s take a closer look at what these numbers mean in context, and dive into some of the details of how containers and the cloud have grown into such integral parts of IT together.
Containers in Context: The Growth of Cloud-Native Technology
Cloud computing was a paradigm shift in infrastructure management, introducing a demand-based, self-service provisioning and consumption model that was highly scalable and, if managed properly, highly cost efficient.
Cloud-native technologies built on this foundation offer a new approach to application development and lifecycle management—an approach that abstracts the infrastructure layer from the application and control layers. Containers, microservices, and serverless functions are infrastructure-agnostic building blocks that are updated, controlled, reconfigured, and scaled independently, with API calls triggering and coordinating their activities into a coherent application experience.
Cloud-native technologies deliver the speed, automation, efficiency, scalability and portability that modern enterprises need to accelerate their business outcomes. These technologies are also critical to today’s AI, IoT, and edge computing workloads. However, the rise of cloud-native technologies and the highly distributed applications based on them has forced organizations to face the challenges of storing, managing, and protecting persistent data sets across complex hybrid and multicloud architectures.
Containers and Data Storage in Stateful Applications
Container development started going mainstream when Docker came along to standardize container runtimes and provide a container management framework, one host machine at a time. The next boost came from the emergence of Kubernetes, the container orchestration platform that simplifies the creation and deployment of multiple container instances across a cluster of machines—at scale and with high fault tolerance.
It is important to remember, however, that containers were initially intended for use in the context of ephemeral stateless web applications. Because stateless applications don’t maintain accounts of individual client sessions, running instances of an application are able to process any requests that come in. This is great for horizontal scale-out across the cluster. But a clear indicator of containerization maturity is that more and more containerized applications are stateful, which means that their data must persist beyond the lifespan of the container.
To this end, Kubernetes has introduced the container storage interface (CSI) for dynamically provisioning persistent volumes that retain data after the pod has been terminated. CSI, which abstracts storage consumption from the other application layers, is based on persistent volume claims (PVCs).
Beyond Basic Data Storage
According to the 451 Research report, 46% of organizations using containers are leveraging public cloud resources as their primary approach to container storage. However, given the popularity of hybrid cloud environments, it is likely that many of these organizations must manage their stateful applications across both public cloud and on-premises storage infrastructures.
What we can draw from this information is that organizations using containers require data management platforms that can support seamless containerized application, data portability, and availability across multiple locations and environment types—all within a consistent management interface and at the required performance SLAs.
In addition to smoothly managing storage resources and processes, container data management solutions have to support the same enterprise-grade disaster recovery and business continuity objectives that are required for legacy applications. No matter the application type, lost or corrupted data is very costly to an organization in terms of lost productivity, reputation damage, and lost revenue. In fact, according to the 451 Research report, 34% of enterprises identify meeting disaster recovery requirements as one of their top storage-related pain points.
It is also interesting to note in Figure 3 that the storage pain point most frequently cited by enterprises (53%) is growing capacity in order to meet the exponential growth in data. Seamlessly supporting the management of ever-growing storage capacity requires highly robust and scalable data management solutions.
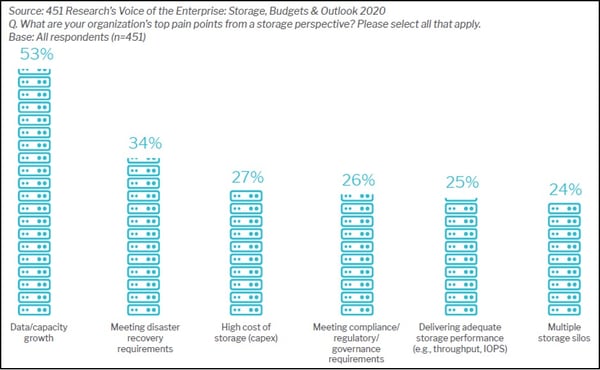 Figure 3: Top Storage-Related Pain Points
Figure 3: Top Storage-Related Pain Points
In short, highly distributed containerized apps, often deployed across multiple clusters and VMs, demand new data management approaches and tools. For instance, protecting containerized and other highly distributed applications requires more application-centric backup and recovery processes than the volume-centric approaches that prevail in legacy data protection systems.
NetApp Cloud Volumes ONTAP and Kubernetes
To help you deal with the demands of containerized deployment, NetApp developed an open-source provisioner technology called Trident. Trident is a CSI-compliant external dynamic storage orchestrator for Kubernetes that supports all of NetApp’s major storage platforms, including Cloud Volumes ONTAP. 600+ NetApp customers are currently managing more than 6 PB of data with Trident. Read more about how Cloud Volumes ONTAP and Trident enhance Kubernetes deployments with persistent volumes for stateful apps.
For more detailed information on Kubernetes persistent storage best practices and how NetApp Trident works with Cloud Volumes ONTAP to dynamically provision persistent storage volumes, see our ebook: The NetApp Guide to Kubernetes: Persistent Volumes, Dynamic Provisioning, Cloud Storage.

