Share
Since it was introduced almost 20 years ago, NetApp FlexClone technology has been used to efficiently replicate workloads in various information technology environments. A FlexClone can rapidly create a readable, writeable copy of a volume from an existing NetApp Snapshot copy of a preexisting flexible volume. This action saves storage space and time, by only having to store the new changes to the cloned volume, while maintaining existing data sets in the source volume. This technology has been used in the past to almost clone a single virtual machine instantly to hundreds or thousands on demand; or to also quickly duplicate a volume of real-world data that can then be used by teams of developers in their test or staging environments.
-1.jpg?width=624&name=image%20(3)-1.jpg)
It is this latter example that we are going to explore a bit further in this entry of our blog series where we have been highlighting features and use cases for NetApp Astra Control for DevOps engineers. In the first blog, we showed how you could utilize the Astra Control Python SDK to automate calls for application backups into a Jenkins CI/CD pipeline. In the second blog, we showed how we could use Jenkins and automate the cloning of a production app for post-mortem analysis, while also restoring a backed-up version of the application that was created during our previous development efforts. The default backup and restore methods available in NetApp Astra Control make use of an S3 bucket to copy both persistent volume data, and application metadata to a centralized location so that they can be easily restored to either the same or a remote Kubernetes cluster. While this makes the Astra Control backup and restores process extremely flexible, it can sometimes take a bit longer to perform both actions as it depends upon the transfer time to the defined object storage bucket.
Where NetApp Astra Control brings intelligence to the operation, is that if you clone directly within the same Kubernetes cluster, using the same ONTAP storage backend, then NetApp FlexClone is automatically utilized to clone the application and its data. This can save quite a bit of time in setting up development environments; whether you are cloning a full instance of an application development tool like Jenkins to build your own CI/CD pipeline, or just cloning a specific application you have developed and its associated pods and persistent data volumes. It is the first use case that we wish to explore a bit deeper here and the methods that we make use of to achieve it.
First, we decided to start off this time, not automating our actions through Jenkins using the NetApp Astra Control Python SDK, but instead by making direct REST API calls to Astra Control using Ansible. Ansible is a very powerful tool, and already has several certified modules available to gather information from and manage NetApp products. In this case, however, we rely on the built-in Uri module to make direct calls to the NetApp Astra Control Center instance installed in our Red Hat OpenShift environment through a series of pre-defined playbooks.
Our first playbook creates the request for a new staging environment, which Astra Control provides by using NetApp FlexClone technology to create a duplicate application development environment in its own namespace based on a golden template development environment that has been previously provisioned. This allows the developer to have their own dedicated environment they can then pull their updated code to without the additional tasks involved in deploying the environment fresh. The entire workflow is iterated in the following graphic:
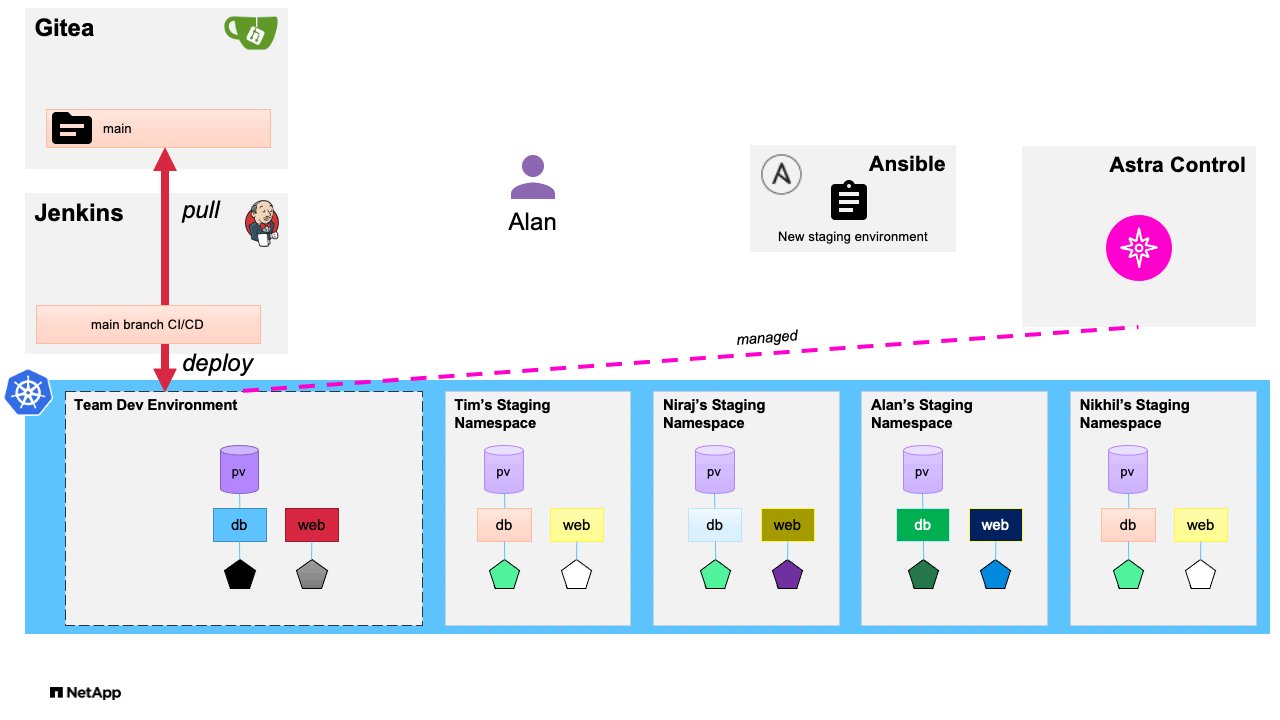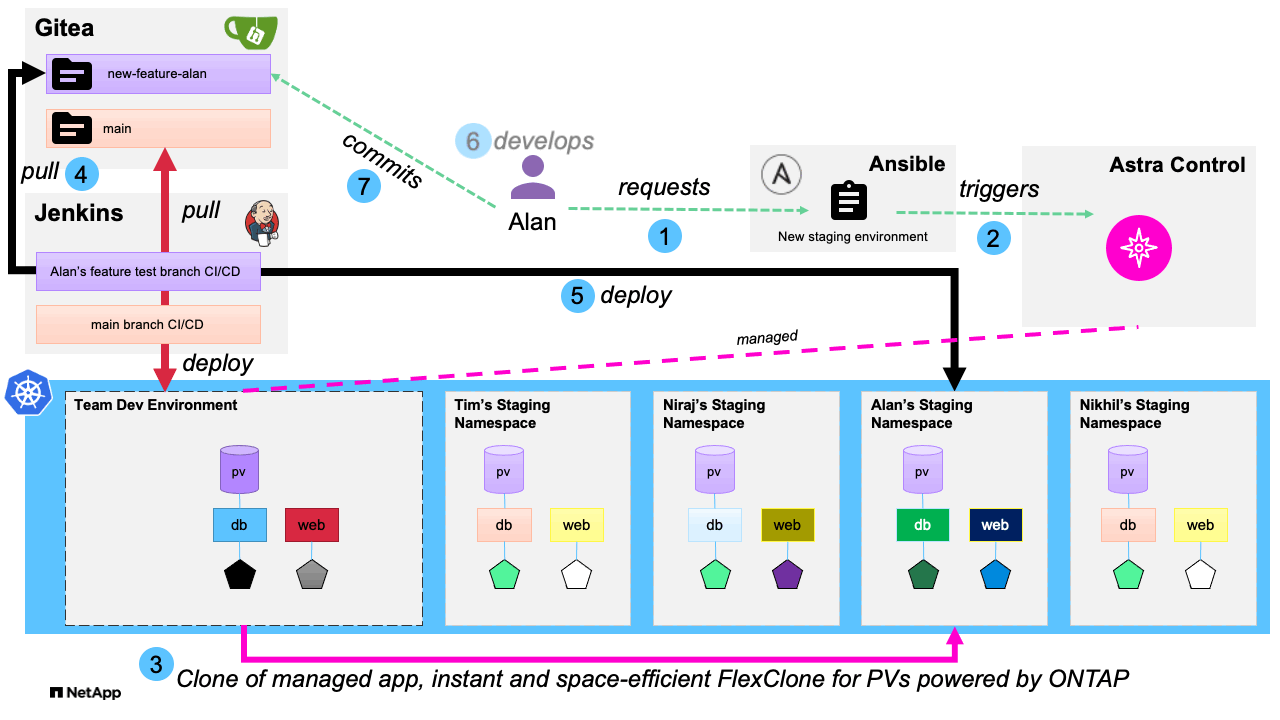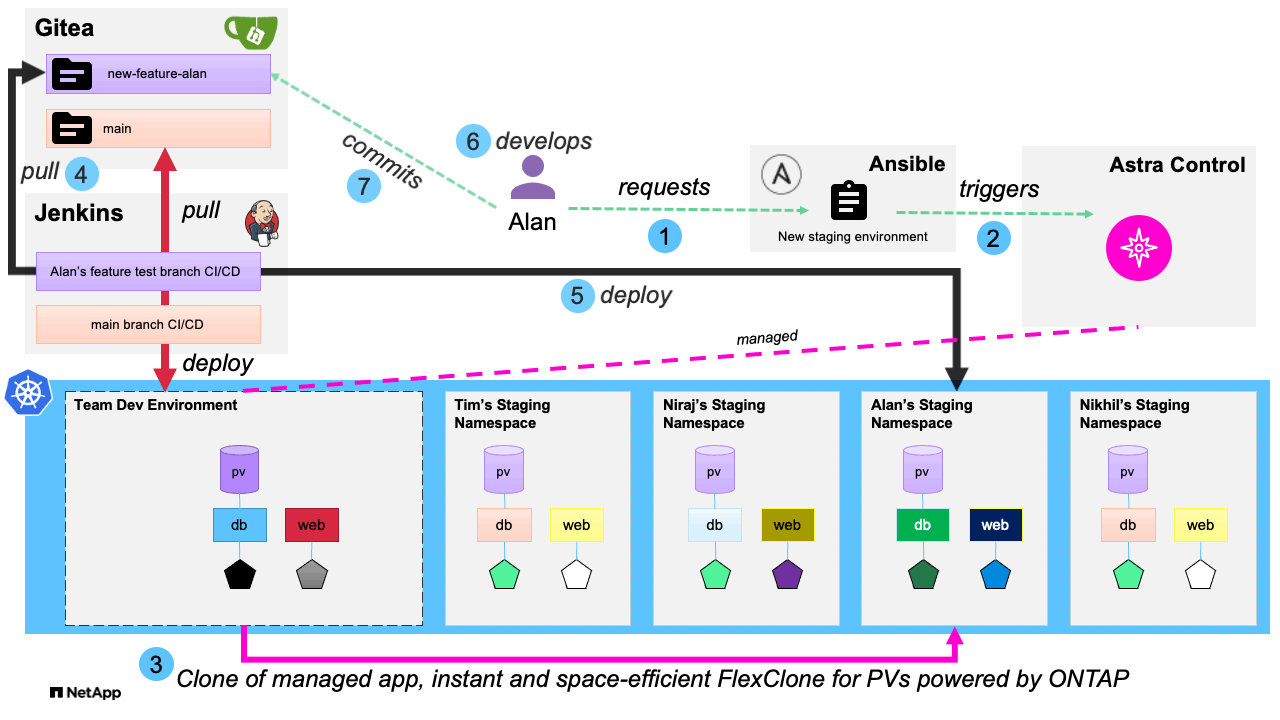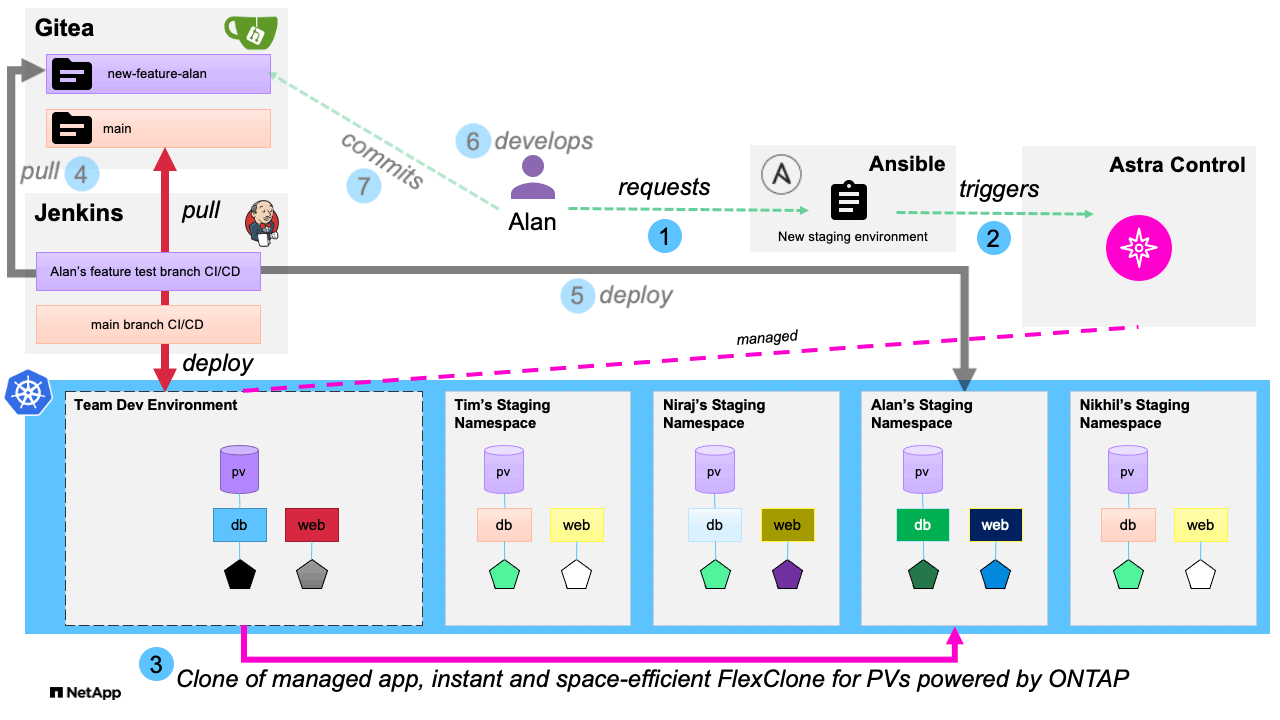
Since the application and its persistent data has been cloned within the same Kubernetes cluster, and because NetApp FlexClone is used to achieve this, we are able to begin working in the new development environment much quicker than if we were to provision a new environment manually by cloning our code from a remote repository and then populating our data volume. An additional advantage of using this method to spawn cloned dev environments is that in addition to the expressed use case of cloning from a golden development environment, NetApp Astra Control with FlexClones also can give us the ability to duplicate and use real-world data in our dev environments for a much more prod-like development experience, by cloning an application in its running state into a dev environment, much like we did with the post-mortem analysis in our second blog. By leveraging Ansible automation in a development environment and utilizing the storage efficiencies provided by NetApp Astra Control and NetApp ONTAP with FlexClone technology, we allow developers to streamline their processes, while also saving time and expenses on the storage backend and resulting in the applications being driven to production in a more rapid manner.
As with our previous blog posts (first and second), we’ve created a video that demonstrates the scenario outlined in this blog, along with automated updating of an application, both using an ansible playbook:

If you’d like to try it yourself, you can find the ansible playbooks referenced in this blog on GitHub, or alternatively:
git clone https://github.com/NetApp-Automation/na_astra_control_suite.git
Or if you would like to write your own automated Astra Control workflows, you can make use of code samples in the Astra toolkits on GitHub, or alternatively:
git clone https://github.com/NetApp/netapp-astra-toolkits.git
For more information about Astra Control, including how to use it in your development projects and to try it for free, visit our Astra page.
If you have questions or comments, join the conversation on the 'astra' channel on the NetApp Discord. And be sure to check the NetApp Cloud blog for future DevOps workflows with Astra.
To learn more about the underlying infrastructure in the environment, visit the Red Hat OpenShift with NetApp solutions page.