Share
In our last blog post in this series, we demonstrated how you can use NetApp Astra Control Center to protect your applications in Kubernetes. We showed how to integrate calls to Astra Control directly into your development workflow by using the Python SDK in the NetApp Astra toolkit. This approach allows you to protect development and production environments by automating on-demand backups during your continuous integration and continuous deployment (CI/CD) process. Astra Control isn’t limited to its use in a Jenkins pipeline, either; you can also create an automated backup schedule and apply it when an application is promoted to production. With this extra layer of application-consistent data protection added to your CI/CD pipeline and your production applications, your development processes will be safe if something goes awry in the process, and you won’t need to worry about business continuity.
As I mentioned in the last post, we discussed how to create and automate these backups in the CI/CD pipeline process—but two questions remain. What good is a backup if you can’t restore it? And how else could Astra help us if something goes wrong with the development process? In this post, we’ll answer both of those questions. We’ll demonstrate Astra Control features that enable us to roll back to our previous production application version. These features let us restore business operations to a normalized state, while also giving us the opportunity to troubleshoot the faulty application, “live.”
Our original pipeline looked something like this: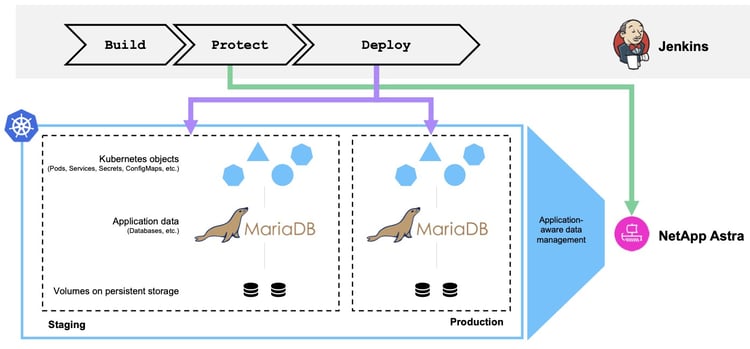
Usually, in a development process, the staging environment is enabled with a brief sample of data for testing application processes. When promoted to production, the application should work the same as it does with the data in the production database. For the sake of this scenario, let’s assume that something is wrong, and the application isn’t behaving as intended. The data being returned by front-end queries doesn’t match the request, and the database has in fact been corrupted.
In a traditional workflow, the development team would attempt to troubleshoot the issue in real time, based on enough bug reports being provided from customers. Or at the first sign of trouble, the team could attempt to redeploy the application to a parallel debug environment to take that process offline. They would redeploy an older code base from a previous version into production, which would restore the application to working order.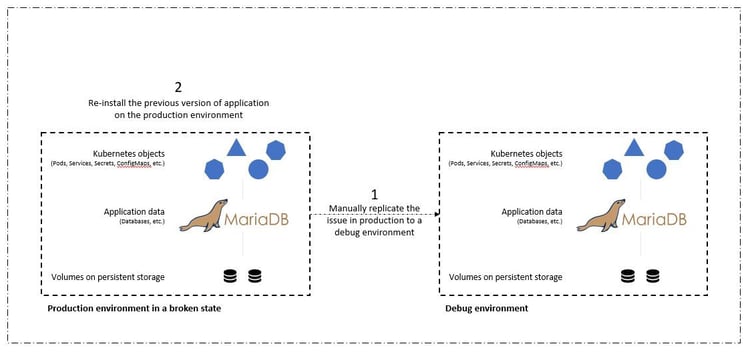
Although this approach would work, we would have to ensure that the state of the broken production app matched that of the version seen in production when the issues occurred. We would also have to spend time promoting the known-good build into production by fetching code from our repository and redeploying the machine images to restore the application to a good running state. Also, in this scenario, we didn’t consider whether the production database itself was corrupted by the faulty code. Ideally, there are separate backup processes in place for the database data too, but must we assume that they’re consistent with the state of the application as it was published? This is where the benefits of stateful and application-consistent backups and clones with Astra Control really show their value.
First, we can use Astra Control to facilitate post-mortem analysis on the state of the application. We do this by cloning the buggy production version to a parallel testing environment in an application-consistent manner. Having this environment set aside in its bug-ridden state will enable us to troubleshoot the problem in real time. We won’t have to try duplicating bug reports in our staging area, and we won’t need to have a buggy version of the application available in production, while we’re troubleshooting.
In the latest version of Astra Control Center (21.12), NetApp introduced the ability to restore a backup directly to a preexisting namespace. Astra Control allows us to choose from our last acceptable backup (that preceded the afflicted version of code) and restore it directly back to the production namespace. The restored version assumes the position of the previous buggy production application, in an application-consistent and stateful manner, including the ingress IP previously assigned. As a result, customers accessing the front end would be unaware of the transition to the backup version.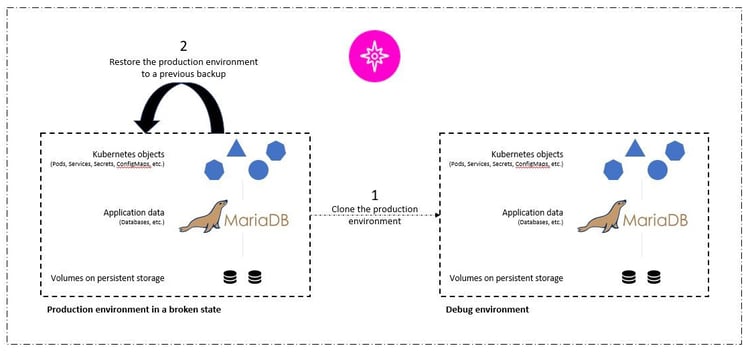
These two operations in tandem expedite our return to normal business operations. In addition to manually orchestrating the process just described, you can also automate the workflow in a CI/CD pipeline by using the Python SDK for Astra Control. This approach would automatically perform both the production cloning and the restore from backup.
As with our first blog post, we’ve created a video that demonstrates the scenarios and restorative actions outlined in this blog, automated through a Jenkins pipeline:

If you’d like to try it yourself, you can find code samples in the Astra toolkits on GitHub, or alternatively:
git clone https://github.com/NetApp/netapp-astra-toolkits.git
For more information about Astra Control, including how to use it in your development projects and try it free, visit our Astra page. If you have questions or comments, join the conversation on the 'astra' channel on the NetApp Discord. And be sure to check the NetApp Cloud blog for future DevOps workflows with Astra. To learn more about the underlying infrastructure in the environment, visit the Red Hat OpenShift with NetApp solutions page.