Share
Do you have a plan for how to keep your business running as usual in case of a disaster strike? If not, it’s high time you had one. Data corruption, the growing number of cyberattacks, natural disasters and failed components are some of the reasons to lay down a business continuity strategy. One part of that plan will be managing the seamless disaster recovery failover and failback between your DR copy and your primary workload.
In this article, we will explain how you can use the cloud to store as your disaster recovery site, and how with the help of NetApp’s Cloud Volumes ONTAP you can manage a seamless disaster recovery failover and failback process for DR.
Failover and Failback Cloud Disaster Recovery
Establishing a disaster recovery (DR) site is a mandatory ask, but the next important question to answer is whether the DR site should be hosted in the cloud or on-premises. Additionally, what if you are running a multicloud environment, where some of the workloads are hosted on AWS and others on Azure? Where should the DR site be located in that scenario?
A cloud-based disaster recovery site built on AWS disaster recovery or Azure disaster recovery resources has multiple advantages compared to an on-premises DR setup. Let’s take a look at a couple of them below:
Economics: You need NOT invest upfront in constructing the building, buying storage, racks, servers, network appliances, HVAC, and human resources. Using a cloud-based infrastructure saves money by allowing you to leverage a pay-per-use model and get your DR copy running in much less time.
 Highly Available and Scalable: With a cloud-based DR model, data can be saved across multiple geographies, a critical aspect for running your DR site, thus, providing the high availability for your workloads at a click of a button. Also, the cloud is highly scalable, allowing resources such as CPU, memory, and storage to be augmented on the fly.
Highly Available and Scalable: With a cloud-based DR model, data can be saved across multiple geographies, a critical aspect for running your DR site, thus, providing the high availability for your workloads at a click of a button. Also, the cloud is highly scalable, allowing resources such as CPU, memory, and storage to be augmented on the fly.
But for cloud-based DR, NetApp offers something even more effective for DR: Cloud Volumes ONTAP®, a virtual appliance running in the cloud, which provides a single pane of glass for your hybrid cloud management. It is a simple, secure, and enterprise-ready DR solution which offers multiple advantages, with seamless disaster recovery failover and failback being one of the most important.
Cloud Volumes ONTAP uses a NetApp feature called SnapMirror® for data replication. SnapMirror replicates the data between the primary site and DR site using ONTAP snapshot technology: the first snapshot is taken to synchronize the data between the two sites, and subsequent snapshots keep the DR site up to date incrementally, only syncing over the changes that happen at primary site. These syncs are cost effective thanks to Cloud Volumes ONTAP’s powerful storage efficiencies.
While it is possible to initiate a SnapMirror manually, it typically works in an automated way: you schedule the data synchronization through a user-friendly wizard, defining your preferred time and frequency for data replication, and rest is taken care of. It operates in an asynchronous mode, where snapshots are replicated to the DR site at a predefined interval.
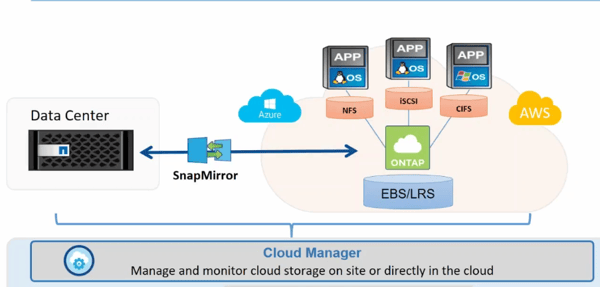
In the event of a disaster, you can failover your operations to your DR systems assured that your data is ready and available on your NetApp Cloud Volumes ONTAP. SnapMirror relationships can be broken using the OnCommand Cloud Manager, System Manager, CLI, or API, immediately making the DR secondary copy read/write ready.
Once that disaster has been addressed, you can failback your operation to the primary site. SnapMirror makes the resynchronization process to failback to the primary or alternate site a simple process. Both failover and failback processes can be started with the help of a few clicks in the GUI, or automated through the use of the APIs.
There are multiple scenarios for initiating the failback process:
- In the case where your primary site has been restored after a disaster and you want to resync the changes from on the secondary site to primary site, SnapMirror looks for the most recent common snapshot and resyncs the data from the DR site to primary site from that last consistent state.
- In the case where a primary site is completely corrupted and can’t be restored, SnapMirror will initiate the complete transfer of data from the DR site back to primary site or an alternate site.
- The last scenario for failback can be combination of the two mentioned above: some of the data in the primary site has been corrupted, and SnapMirror will resync the data from last consistent state, before the data was corrupted.
More Disaster Recovery in the Cloud Benefits with Cloud Volumes ONTAP
 Cloud Volumes ONTAP works with both Azure storage and AWS storage. In addition to its disaster recovery failover and failback capabilities, it offers lot of other benefits. In this section we will talk about some of those benefits:
Cloud Volumes ONTAP works with both Azure storage and AWS storage. In addition to its disaster recovery failover and failback capabilities, it offers lot of other benefits. In this section we will talk about some of those benefits:
- Cost effective: DR setup comes in use only in case of a disaster, so is it a good idea to pay month-by-month storage expenses in the cloud even without using it? Cloud Volumes ONTAP provides data tiering to automatically transfer the cold data (data not often in use) from the Amazon EBS performance tier to a cold storage tier on Amazon S3, the low-cost storage offering by AWS. Additionally, in case of a disaster, DR data can be configured to automatically move from Amazon S3 to Amazon EBS to provide high performance. Using data tiering, the overall DR storage expenses can be as low as $0.03 per GB per month.
- Low bandwidth requirements: Data replication with SnapMirror happens after data deduplication and compression of data blocks. Once enabled, deduplication works automatically and reduces the data storage requirements by removing the duplicate data and by transmitting only single copy of the data block. Similarly, compression reduces the storage requirements by compression the data before initiating the replication. Thus, these storage efficiencies lead to an overall reduced bandwidth requirements and cutting cloud storage costs and expenses by 50% or more.
- Validating DR Readiness: NetApp FlexClone technology can be used in conjunction with SnapMirror to test the DR readiness. With FlexClone, no additional storage is required to have another read/write copy of your production data available. This copy can be used for development and testing related activities, including DR testing. Clones come up quickly and can be destroyed once testing in over. DR testing is one key aspect of a BCP that should be a regular practice. It can save your company from potential embarrassment and financial and reputation losses.
 Companies that have turned to NetApp and Cloud Volumes ONTAP have been able to effectively secure their DR capabilities and ensure that they operate in worst case scenarios. One example of a company that did that is NetApp customer Trinity Mirror, the largest news media business in the UK. Trinity Mirror moved to Cloud Volumes ONTAP on AWS when their primary goal was to cut down costs, while retaining all of the capabilities to protect the data their 40 million monthly users rely on.
Companies that have turned to NetApp and Cloud Volumes ONTAP have been able to effectively secure their DR capabilities and ensure that they operate in worst case scenarios. One example of a company that did that is NetApp customer Trinity Mirror, the largest news media business in the UK. Trinity Mirror moved to Cloud Volumes ONTAP on AWS when their primary goal was to cut down costs, while retaining all of the capabilities to protect the data their 40 million monthly users rely on.
Summary
A DR failover scenario is always a dangerous situation for a company to be in. Cloud Volumes ONTAP offers you a way to keep your data protected in such events, and additional features such as storage tiering, compression, and data deduplication that can reduce the storage cost by more than 50%.
If you are already using ONTAP, this is the right time to move your disaster recovery site to Cloud Volumes ONTAP and make it an integral part of your Azure disaster recovery plan or AWS disaster recovery plan. Since the user interface is the same, there’s no need to train your admins to use a new set of tools and processes, which can save time and costs, specifically the cost of disaster recovery.

