Share
Business organizations make use of applications that require different levels of availability and different SLA objectives. How critical or demanding an application is considered is proportional to its requirements in throughput, responsiveness, and recovery time in case of a failure. The same considerations hold true when forming AWS high availability best practices.
Depending on the deployment’s specific requirements, distributing compute and storage across AWS Availability Zones in combination with Placement Groups is a way to address this challenge in AWS high availability. An optimized combination of those options, along with a Cloud Volumes ONTAP HA deployment, can meet the requirements presented by each layer.
In this article we are going to review these AWS high availability best practices and use cases for single and multi Availability Zones, and Placement Groups. We’ll also look at the added benefits that Cloud Volumes ONTAP HA can bring as a solution at the storage level.
In this article, you will learn:
- What are AWS Regions and Availability Zones?
- Parameters to Consider When Choosing an AWS Region
- What is a Multi-AZ Deployment?
- AWS Placement Groups
- Cloud Volumes ONTAP HA for AWS
What are AWS Regions and Availability Zones?
Availability zones are highly available data centers within each AWS region. A region represents a separate geographic area. Each availability zone has independent power, cooling and networking. When an entire availability zone goes down, AWS is able to failover workloads to one of the other zones in the same region, a capability known as “Multi-AZ” redundancy.
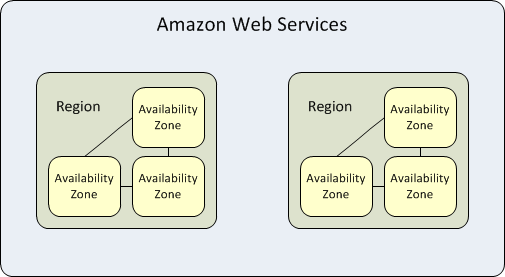
Each AWS region is isolated and operates independently from other regions but the availability zones within each region are connected via low-latency links to provide replication and fault tolerance. If you host all your data and instances in a single availability zone, which is affected by a failure, they would not be available.
The purpose of this isolation is to serve workloads with high data sovereignty and compliance requirements that do not permit user data to pass outside of a specific geographic region. These types of workloads benefit from the structure of the AWS availability zones with low-latency and complete separation from other regions.
See a full list of available regions within the AWS global infrastructure.
AWS Regions vs. Availability Zones
There are two key operational differences between running your workloads in different regions vs. different availability zones within the same region.
Geographical Distribution
The geographical distribution of AWS regions and availability zones also plays a significant role in the performance and reliability of your applications.
If you deploy your application across multiple availability zones in a single region, you can achieve a certain level of high availability and fault tolerance, but lower than that provided by deploying in different regions. If one availability zone fails, your application can continue to run in another availability zone without any interruption. However, if the entire region fails, your application will fail.
On the other hand, deploying your application in multiple regions means that even if an entire region fails (a very unlikely scenario), your application can continue functioning. Deploying across regions provides additional benefits such as reduced latency for your global users and faster disaster recovery.
Compute and Data Transfer Cost
When it comes to cost, the location of your AWS resources can have a significant impact. Each AWS region has different pricing for services due to factors such as local demand, infrastructure costs, and local tax laws. For instance, running an EC2 instance in the Asia Pacific (Mumbai) region is likely to cost more than running the same instance in the US East (N. Virginia) region. However, the cost of running workloads across different AZs in the same region is generally the same.
Also, data transfer costs can vary depending on whether the data is transferred within the same region, between different regions, or between regions and the public internet. Transferring data within the same region or between availability zones in the same region is generally cheaper compared to transferring data across regions or to the public internet.
Parameters to Consider When Choosing an AWS Region
Some parameters are key to consider before choosing an AWS region and AZ to host and deploy your application in order to get the best results.
The following list provides the most important parameters to take into consideration:
Parameter #1: Latency and proximity—opt for the closest region for low latency.
Fast connection to the server ensures better performance in terms of quick loading and transfer times which results in overall better user experience. You can achieve this by choosing an AWS region that is closest to the majority customer base. The shorter the distance between the cloud and the end user, the lower the latency. For example, if most of your customers access your application within the North American region, choosing an availability zone within the regions of the US or Canada will generate the best results.
Prices of AWS service vary depending on the region based on elements like the cost of physical infrastructure and taxes. The difference between various regions can amount to hundreds of dollars, so choosing the right one is key to reducing unnecessary costs. You can use the official price calculator to see which region best suits your needs. Also check out NetApp’s AWS Calculator, which lets you calculate TCO including the cost of storage services.
Parameter #2: Cost—pick a region that offers the best price-performance ratio.
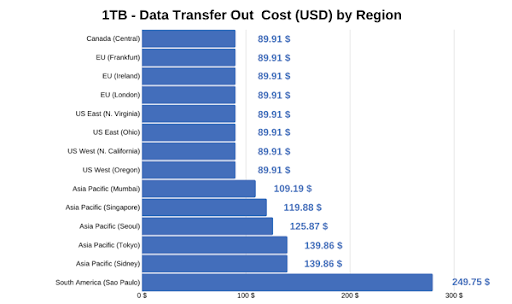
Below is a table for reference that shows the various prices for each region for a 1TB data transfer.
Parameter #3: Regulatory compliance and security—protecting company assets
Every country or union has a different set of compliance norms and rules to protect user data. Some regions might prohibit the transfer between their region and other regions. A violation of such compliance regulations may lead to lawsuits and result in critical financial and reputational damage to your organization. Additionally, if you offer worldwide services, you should consider using multiple AWS regions and availability zones to offer the fastest and most reliable service to your customers.
Parameter #4: Service Level Agreements (SLA)—right parameters to get better service.
AWS services offer different SLAs based on their unique availability and parameters. AWS will abide SLA best when you deploy the application according to AWS design. Take all other parameters into consideration along with your requirements when selecting a region and an AZ to ensure they offer the best solution to host and deploy your application.
What is a Multi-AZ Deployment?
When it comes to mission critical workloads, such as enterprise databases—whether hosted on Amazon EC2 instances or on Amazon native database services (such as Amazon RDS)—a multi-AZ distribution model gives you high availability in case a major failure occurs in an entire Availability Zone.
Critical production applications that can’t afford even a moderate amount of downtime benefit from this model and have to consider this type of general failure as a real possibility. The same goes for the upper tiers that this application may be composed of. If the web services of an app are all hosted in one AZ, having the underlying databases in an HA multi-AZ configuration won’t help much if the web tier is hosted in only one AZ.
From this high availability perspective, in a single AZ deployment, if the AZ goes down everything goes down and the Recovery Time Objective goes way higher. This not to mention the data loss that will take place in-between.
Other important benefits from having multi-AZ deployments include:
- No I/O delays during backups, as backups are taken from the standby instance.
- No interruptions to I/O when applying patches or performing upgrades for maintenance purposes.
- Increase in responsiveness when load balancing is used. If one AZ is constrained, the instances in other zones can digest the traffic.
Of course, not all application use cases require a multi-AZ deployment. Temporary tests, dev deployments, or any use case that is not critical can get hosted in a single AZ and avoid the additional costs that come with running a multi-AZ. There are even high-intensive, extreme-low-latency use cases that fit the single-AZ model better.
AWS Placement Groups
Simply put, a Placement Group is a configuration option that AWS offers which lets you place a group of interdependent instances in a certain way across the underlying hardware on which those instances reside. The instances could be placed close together, spread through different racks, or spread through different Availability Zones. Let’s take a closer look at each one of the Placement Group types you can choose from and types of workloads that would best fit into each distribution option:
1. Cluster Placement Groups
The cluster placement group configuration allows you to place your group of interrelated instances close together in order to achieve the best throughput and low latency results possible. This option only lets you pack the instances together inside the same Availability Zone, either in the same VPC or between peered VPCs.
The advantage with cluster placement groups is that the communication between those instances is not limited to single-flow traffic of 5 Gbps but to 10 Gbps single-flow (point-to-point) traffic and a total of 25 Gbps for aggregate traffic. HPC (High Performance Computing) network-bound applications are the best use cases for this deployment model. Computational engineering, live event streaming, genomics sequencing, astronomy models, and earth-climate compute models are examples of use cases for this type of grouping in the cloud.
2. Partition Placement Groups
With partition placement groups, you can group your instances in separate logical partitions that form the placement group. The idea of this is to have each one of the logical partitions built on top of separate hardware racks in order to avoid common hardware failures. If one rack fails, it will only affect the instances residing on this logical partition. Each logical partition is composed of multiple instances. The partition placement group option allows you to place those partitions within a single AZ or in a multi-AZ setup within the same region.
So, what type of loads would best fit this model? Big data stores which need to be distributed and replicated are good examples. Big file systems such as HDFS or Cassandra are also great fits. Partition placement groups allow you to see which instances are placed into which partitions so you can make Hadoop or Cassandra topology aware and configure data replication properly. Any use case needing big data analysis, data reporting, or large-scale indexing would also be a good fit for partition placement groups.
3. Spread Placement Groups
With spread placement groups, each single instance runs on separate physical HW racks. So, if you deploy five instances and put them into this type of placement group, each one of those five instances will reside on a different rack with its own network access and power, either within a single AZ or in multi-AZ architecture.
The spread placement group setup may be similar to partition placement groups, but the main difference is that partition placement groups are made of several instances on each partition, while spread groups are just single individual instances spread through different racks or AZs.
This model is recommended for a small number of critical instances for your business. You could maybe have a small amount of SQL database instances running here or your web application tier. This setup is an ideal use case for redundancy since there is less requirement for the beefy computational power offered by partition and cluster placement groups.
Cloud Volumes ONTAP HA for AWS
The Cloud Volumes ONTAP HA configuration provides AWS high availability. Running on dual nodes of Amazon EC2 compute instances and storing all the data in the underlying Amazon EBS storage, operations can prevent any data loss from occurring in a failure and recover in less than 60 seconds.
In this Cloud Volumes ONTAP pair, all the data is mirrored between the two nodes, in either an active-active configuration, where both nodes serve clients, or in an active-passive configuration, in which one node is the standby. In both cases the data is synchronously mirrored each time there is new data written. This configuration can also be deployed either in a single AZ scenario or in a multi-AZ scenario:
- Single-AZ: Both Cloud Volumes ONTAP nodes reside on the same Availability Zone. NetApp Cloud Manager automatically deploys both nodes with a spread placement group configuration in order to avoid common compute failures.
- Multi-AZ : Each Cloud Volumes ONTAP node resides in a different Availability Zone, again eliminating the AZ as a single point of failure, which is not a feature that the native Amazon EBS storage replication offers. With this type of high availability configuration you need to set up an AWS Transit Gateway with floating IP addresses for the failover to work properly and provide permanent NAS or any data access.
Cloud Volumes ONTAP HA needs three Amazon EC2 instances to get working: two main nodes doing all the storage work and one small mediator t2.micro instance in charge of regulating and administering the automatic failover and failback related tasks. RPO (Recovery Point Objective) is zero, your data is always consistent since it is synchronously mirrored, and your RTO (Recovery Time Objective) is 60 seconds or less for data to be available again in case of a failover to the other node.
AWS has other native storage layer redundancy features such as Amazon EBS. As mentioned earlier, Amazon EBS only replicates within servers on a single Availability Zone and if you were to provide redundancy at the storage level by only using Amazon EBS, you would need to take Amazon S3 snapshots and transfer them over to a different Availability Zone, which has also an additional cost. Other AWS native high-availability features such as Amazon EFS export the stored data only through NFS, and it currently does not support Windows instances.
Conclusion
All the information provided in this article about AWS high availability best practices drives us to three main conclusions:
- Wherever there is a multi-AZ configuration present, an additional reliability point is scored as the entire Availability Zone itself is ruled out as a single point of failure.
- Different workloads have different sets of requirements which can fit better into either single-AZ deployments or multi-AZ deployments.
- Whenever centralized storage is needed, Cloud Volumes ONTAP HA is a solution that brings redundancy and fast recovery at the storage layer, whether you are deploying in a single-AZ modality or in a multi-AZ one. This at a lower or comparable price compared to running on raw Amazon EBS storage.
Your business continuity is important. Cloud Volumes ONTAP gives you the ability to ensure it.
