Share
What Is FSx for Lustre?
Amazon FSx for Lustre helps organizations run, launch and scale popular high-performance file systems.
The open-source Lustre file system is for the use of Linux-based applications that demand large scale and fast storage—when you need your storage to keep pace with your compute. Lustre was designed to deal with the issue of speedily and cheaply processing large data sets. It is widely used in super computing and HPC projects, including many of the 500 most powerful computing clusters in the world.
Amazon FSx for Lustre is a fully managed service that makes Lustre easily accessible. It lets organizations use Lustre for workloads on the AWS cloud, where storage speed is important. Amazon FSx for Lustre avoids the traditional complexity of managing and setting up high-performance Lustre file systems. It lets you spin up, scale, and run a reliable high-performance file system in minutes. You can also use its multiple deployment features to optimize costs for your organization’s requirements.
Amazon FSx for Lustre integrates with Amazon S3, so you can process cloud data sets with the Lustre high-performance file system. When connected to an S3 bucket, an FSx for Lustre file system transparently shows S3 objects as files and lets you write data modified by Lustre back to S3.
In this article:
- When to Use Amazon FSx for Lustre?
- How Amazon FSx for Lustre File Systems Work
- Deployment Options for Amazon FSx for Lustre
- Amazon FSx for NetApp ONTAP
When Should You Use Amazon FSx for Lustre?
Here are a few common use cases of Amazon FSx for Lustre.
Machine Learning
Machine learning workloads rely on massive volumes of training data. These workloads tend to use shared file storage, because multiple compute instances must process training datasets simultaneously. Therefore, FSx for Lustre is suitable for machine learning workloads, providing shared file storage with consistent, low latency, and high throughput. FSx for Lustre is integrated with Amazon SageMaker, letting you speed up your training tasks.
High Performance Computing
High Performance Computing (HPC) lets engineers and scientists solve compute-intensive, intricate problems. HPC workloads like genome analysis and oil and gas discovery process huge volumes of data, requiring very fast access by multiple compute instances.
FSx for Lustre is suitable for scientific computing workloads and HPC. It is a file system optimized to reduce cost and improve performance for high-performance workloads, which can be accessed by thousands of EC2 instances. FSx for Lustre integrates with AWS Batch and AWS ParallelCluster, which makes it simpler to employ with HPC workloads.
Media Processing and Transcoding
Media data processing workflows, such as visual effects, video rendering, and media production, require storage and compute resources to deal with the large amounts of data being generated. FSx or Lustre offers the low latencies and high performance required for distributing, analyzing and processing digital media files.
Autonomous Vehicles
Organizations creating autonomous vehicle systems generally test models by running training and simulations on huge amounts of camera and vehicle sensor data. This helps ensure the safety of the vehicles. FSx for Lustre lets you access that data concurrently from thousands of high-performance nodes. This lets you accelerate model development and run simulations at scale.
Big Data and Financial Analytics
Big data analytics use cases, such as financial analysis and SAS Grid workloads, generate large volumes of data that drive data-intensive applications. This data requires high-performance storage, while processing the growing amounts of data can be complicated and costly. Amazon FSx for Lustre is able to process big amounts of data at scale and is cost and performance-optimized.
Electronic Design Automation
EDA is used to simulate failures and performance in the design stage of the silicon chip production process. It is a high-performance application. FSx for Lustre gives you the flexibility and performance to design and evaluate new products, innovate more quickly, and scale to fulfil demand.
Related content: learn about Amazon FSx for Windows, Amazon’s companion service for business application use cases
How Does Amazon FSx for Lustre Work?
Amazon FSx for Lustre, based on Lustre, is a high-performance file system. It has scale-out performance, which increases linearly according to a file system’s size. Lustre file systems scale horizontally over multiple disks and file servers.
This scaling provides each client with access to the data retained on each disk, which removes many of the bottlenecks of traditional file systems. Amazon FSx for Lustre extends Lustre’s scalable architecture to allow for high levels of performance over large amounts of clients.
Each Amazon FSx for Lustre file system is made up of the file server which clients communicate with, and a series of disks connected to each file server that retains your data. Each file server uses a fast, in-memory cache to optimize performance for the most regularly accessed data.
HDD-based file systems may be provisioned using an SSD-based read cache to enhance performance further, for the data that is accessed most often. When a client retrieves data that is stored in the SSD or in-memory cache, the file server isn’t required to read it from disk. This minimizes latency and increases the total throughput.
The diagram below demonstrates the paths of a read operation served from a disk, a write operation, and a read operation served from SSD or in-memory cache:
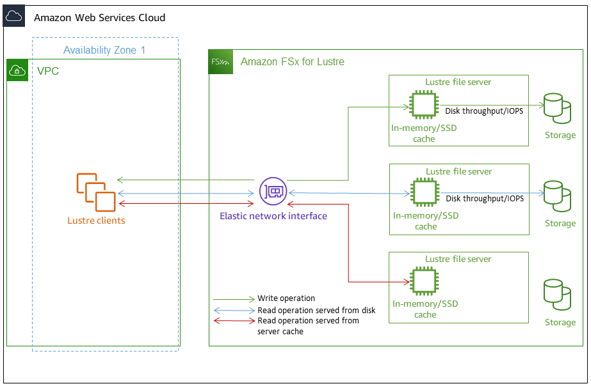 Image Source: AWS
Image Source: AWS
When you read data that is retained on the file server’s SSD or in-memory cache, file system performance is subject to the network throughput. When you read data that is not stored on the in-memory cache, or write data to your file system, file system performance is affected by lower disk throughput and network throughput.
Amazon FSx for Lustre Deployment Options
Amazon FSx for Lustre has two types of file system deployment: scratch and persistent.
Scratch File Systems
These are designed for shorter-term processing of data and for temporary storage. In the event that a file server fails, data does not persist and is not replicated. Scratch file systems have high burst throughput of as much as six times the baseline throughput of 200 MBps per TiB of storage potential.
When should you use it? Use scratch file systems when you require cost-effective storage for processing-heavy, short-term workloads.
The diagram below illustrates the architecture of an Amazon FSx for Lustre scratch file system:
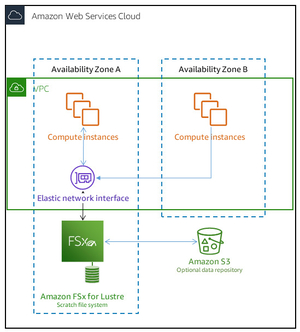 Image Source: AWS
Image Source: AWS
Persistent File Systems
These are designed for longer-term workloads and storage. The file servers remain highly available and data is automatically replicated in the same Availability Zone (AZ) as the file system. The data volumes connected to the file servers are replicated separately from the file system they are attached to.
When should you use it? Use persistent file systems for long-term or indefinite workloads, which could be sensitive to changes in availability.
The diagram below illustrates the architecture for an Amazon FSx for Lustre persistent file system, with highly available, replicated file servers and data volumes in the same Availability Zone:
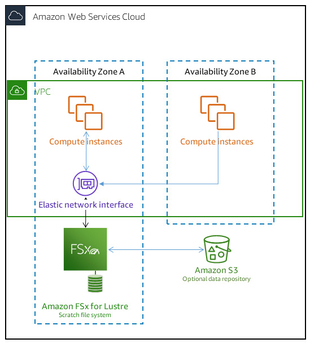 Image Source: AWS
Image Source: AWS
Amazon FSx for Lustre monitors persistent file systems for hardware failures, on an ongoing basis, and automatically changes infrastructure components if there is a failure. If a file server is unavailable on a persistent file system, it is automatically replaced in just minutes. During this time, client requests for data on the server keep trying to be transparent and ultimately succeed once the file server is replaced. The data stored on persistent file systems is replicated on disks and all failed disks are transparently and automatically replaced.
When you develop a new file system, you decide the file system deployment type through the AWS Management Console, the Amazon FSx for Lustre API, or the AWS CLI.
Amazon FSx for NetApp ONTAP
In collaboration with NetApp, AWS has launched Amazon FSx for NetApp ONTAP, a new cloud-based managed shared file and block storage service that brings the best of both worlds to their customers.
FSx for ONTAP delivers NFS, SMB and iSCSI storage powered by NetApp’s advanced data management system, with features and benefits that go beyond other AWS offerings:
- Multiprotocol file and block storage support
- High availability across multi-AZs
- Data protection and disaster recovery features
- Cost-cutting storage efficiencies, automatic data tiering to S3, and instant data cloning
- GUI or RESTful API access, control and automation through NetApp BlueXP Console
- Operation across hybrid and multicloud architectures
Click here for a step-by-step walkthrough on how to set up your own FSx for ONTAP environment with BlueXP Console.

