Share
In this article, we’ll discover components of Amazon Web Service’s massive global infrastructure: Regions, Availability Zones, Services and the Amazon control plane. This architecture was created to provide high availability and resiliency for customer workloads. For an introduction to high availability concepts and how Amazon provides high availability for specific workloads, see our article AWS High Availability.
In this post, we’ll examine AWS high availability architecture, and show how NetApp Cloud Volumes ONTAP can add value to this architecture for enterprise workloads.
In this page:
- Why Is High Availability Important?
- Understanding regions and availability zones
- Amazon’s high availability track record
- AWS high availability best practices
- Make the most of AWS architecture with Cloud Volumes ONTAP
Why Is High Availability Important?
When setting up robust production systems, minimizing downtime and service interruptions is often a high priority. Regardless of how reliable your systems and software are, problems can occur that can bring down your applications or your servers.
Implementing high availability for your infrastructure is a useful strategy to reduce the impact of these types of events. Highly available systems can recover from server or component failure automatically. This is because failures to a single element don’t affect the functioning of the whole infrastructure: if a virtual node goes down, virtual machines failover to other nodes, assuring the continuity of service without interruptions.
Understanding Regions and Availability Zones: Amazon’s Global High Availability Network
Amazon Web Services built a massive global infrastructure to provide high availability and resiliency for customer workloads. Let’s examine the key components of this architecture: Regions, Availability Zones, Services and the Amazon control plane.
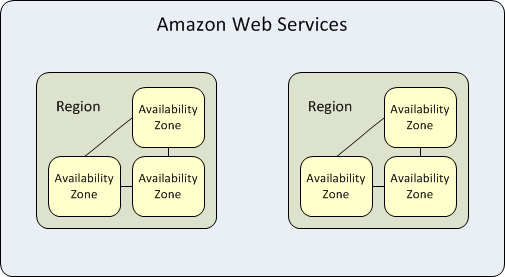
Source: Amazon Web Services
Regions
Amazon provides cloud services in 21 geographical regions (see the Amazon region map). The concept of a “Region” in AWS is different from the same concept used by other cloud providers (see our article on Azure High Availability). Amazon defines a region as a geographical area in which there are at least three separate data centers, called Availability Zones (AZs).
Availability Zones
An AWS Availability Zone is a complete, localized infrastructure with redundant power, networking and connectivity. Amazon currently operates 66 availability zones globally. Each AZ encompasses multiple data centers, typically 3, in the same location. In each region, AZs are separated by a “meaningful distance”, but no more than 100 km, to allow for fast connectivity between them.
Amazon AZs are interconnected with high-bandwidth, low-latency networking, over a dedicated metro fiber cable. Network performance is fast enough to perform synchronous replication between AZs, meaning machine instances or other Amazon services in one AZ can be replicated in real time to another AZ without affecting read or write performance.
By deploying across several AZs, you can protect your applications from natural disasters such as tornadoes and earthquakes. By deploying across regions, you can achieve even higher resilience against disasters that can affect a broader area, such as a war. Amazon offers private, high-speed networking across regions to provide an additional layer of business continuity.
Service Provisioning Across Regions and Availability Zones
Amazon’s policy is to deliver Amazon services, features and instance types across all AWS regions, although full deployment of a new service can take up to 12 months. Some Amazon services are delivered globally and are not deployed in specific regions or AZs, such as Route 53, Amazon WorkMail and Amazon WorkLink.
High Availability for the Amazon Control Plane
The Amazon control plane, including APIs, the AWS Management Console and CLI, is distributed across AWS regions with a multi-AZ architecture, ensuring their continuous availability. This means that organizations that rely on Amazon capabilities in their applications are never dependent on a single data center. It also allows Amazon to conduct maintenance without making critical services unavailable to customers.
Compliance and Data Residency
Compliance standards and regulations often mandate that an organization’s data is stored in a specific geographical location (this is called “data sovereignty”). Amazon provides full control over the AWS region in which data is stored, allowing you to comply with data sovereignty requirements.
Amazon’s High Availability Track Record: Outages and Recoveries
Amazon’s global high availability architecture is massive, robust and in many cases vastly superior to high availability measures most organizations could deploy on-premises. Nevertheless, even a massively redundant system like Amazon Web Services experiences failures. Learning about these failures is instructive, as it will help you understand the weak points of Amazon’s architecture and what you can expect with regards to the actual reliability and resilience of Amazon services.
A timeline of all reported AWS outages between 2014-2018
- November 26, 2014—Amazon CloudFront DNS failed for two hours, many websites and cloud services were knocked offline.
- September 20, 2015—Amazon DynamoDB, a NoSQL database service, experienced a full outage of three hours in one of the AZs of the North Virginia region. The outage was due to a power outage and a problem with power failover procedures. There was also disruption of service to Simple Queue Service, EC2 autoscaling, Amazon CloudWatch and AWS console.
- June 5, 2016—the AWS Sydney region was unavailable for several hours due to thunderstorms in the region which caused a power outage.
- February 28, 2017—Amazon S3, a popular and heavily-used storage service, experienced an outage in the North Virginia region. Other services also went down, including CloudFormation, autoscaling and Elastic MapReduce. The outage was caused by a human error that resulted in an unexpected deletion of machine instances.
- March 2, 2018—the Amazon Direct Connect service experienced degradation and connectivity issues for approximately four hours, due to a power outage in the North Virginia region. This caused service interruptions on EC2, and customers could not remotely access EC2 instances.
- May 31, 2018—some EC2 servers lost power for about an hour, in a single AZ in the North Virginia region. This resulted in service disruption for EC2 instances and degraded performance for EBS volumes.
Key takeaways from the reported outages
- All the outages were resolved within several hours.
- Most of the outages were centered on a single Availability Zone, meaning that any application with Multi-AZ deployment would not have felt them. Only one outage in four years involved an entire AWS region.
- A weak point in Amazon’s infrastructure seems to be distributed services such as Amazon S3 and DynamoDB, which may experience failure and have a chain reaction on other Amazon services, including the Amazon control plane.
- Most of the outages in previous years focused on the North Virginia region. Although this may be coincidental, it may be prudent to ensure Multi-AZ deployment for critical applications running in this region.
AWS High Availability Best Practices
Here are a few best practices you can follow to improve high availability in the Amazon ecosystem:
- Avoid single points of failure—identify elements of your architecture that are critical for applications to function, and ensure they are highly available.
- Multi-AZ for critical components—always place at least one load balancer, application server or database in at least two AZs.
- Have the ability to absorb AZ failures—ensure you have enough capacity, or the ability to automatically increase capacity, in any of your AZs in case of failure in another AZ.
- Use reserved instances—guarantee you can get additional capacity in a specific availability zone and more cost-efficient to support failure scenarios.
- Replicate data across AZs—ensure you have a solid strategy for data replication, either by relying on shared Amazon data services like S3 or EFS, or by attaching machines to EBS volumes and replicating them across AZs or regions.
- Setup monitoring and alerts—Use Amazon services like CloudWatch, together with application or network monitoring tools, to identify service disruption or performance degradation and immediately inform operations staff.
- Automate problem resolution or failover process—AWS provides multiple ways to respond to failure scenarios, including Elastic Load Balancing, autoscaling and automatic failover.
Make the Most of AWS Architecture with Cloud Volumes ONTAP
If your AWS infrastructure powers business critical applications, NetApp Cloud Volumes ONTAP, the leading enterprise-grade storage management solution, provides high availability to ensure business continuity with no data loss (RPO=0) and minimal recovery time (RTO < 60 secs). Add that to data protection with NetApp Snapshot™ technology, which doesn’t require additional storage or impact application performance, and your enterprise is guaranteed to remain in operation and able to recover from any unplanned downtime or disaster event.

