Share
How can you get up to 4,500MiB/s of sequential reads or 470,000 random read IOPS with a single cloud volume? And up to 1,700MiB/s of sequential reads or 220,000 random read IOPS from a single EC2 instance? Read on to find out how we tested the limits of NetApp® Cloud Volumes Service using FIO.
The needs of enterprise application file services differ enormously, defined by workload, team, and required performance intensity. Dev/test production workloads will obviously diverge from the baseline requirements of MapReduce analytics and Oracle Databases. And, of course, not all applications are highly demanding, but…
We’ve decided to re-test the limits of a single cloud volume in NetApp Cloud Volumes Service for AWS. In so doing, we decided to make explicit our testing methodology alongside this explanation of its administration and outcomes, with a link to the testing parameters. This blog is the tool we’ve used to make our methods transparent.
Caveat emptor: testing methodology is everything when discussing limits and expectations. The testing didn’t target any particular application; instead, we chose to focus on the upper limits of both throughput and I/O, making every effort to ensure a full-stack evaluation. When testing storage, we evaluated using realistic sizes for both the chosen dataset—the totality of data in a given file system—and the working set—the portion of the dataset that’s actively read from or written to.
Towards this end, the shown in this paper were achieved using a 1 tebibyte (TiB) working set, which caused I/O to traverse the entire storage subsystem, rather than rely upon data resident in storage memory. Oftentimes, application cache reads in server memory and, as such, a server cache miss will also likely result in a storage cache miss.
Sequential Scale Out Workload Study
-1.png?width=488&name=ggg%20(1)-1.png)
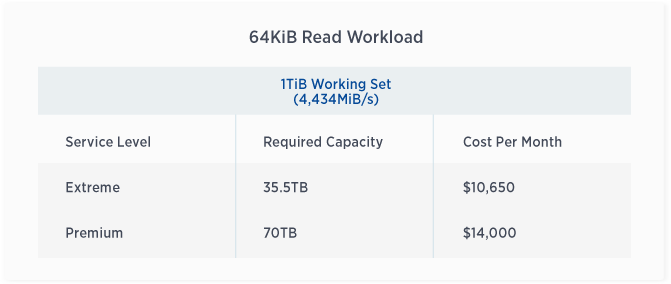
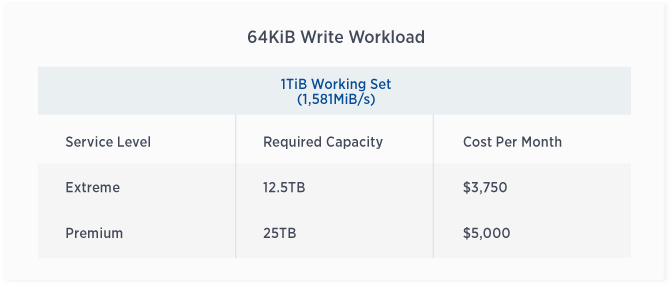
The following tables offer additional insight into the throughput detailed above. They indicate the service levels offered by NetApp Cloud Volumes Service, as well as the associated capacity and cost per month. In Cloud Volumes Service, users are able to dynamically increase or decrease service levels and allocated capacity as frequently as desired, meaning that the cost shown in the chart below will only be incurred if the capacity/service level is steadily maintained for an entire month. Thus, you can easily right size your performance at a fair price point.
64KiB Read Workload
64KiB Write Workload
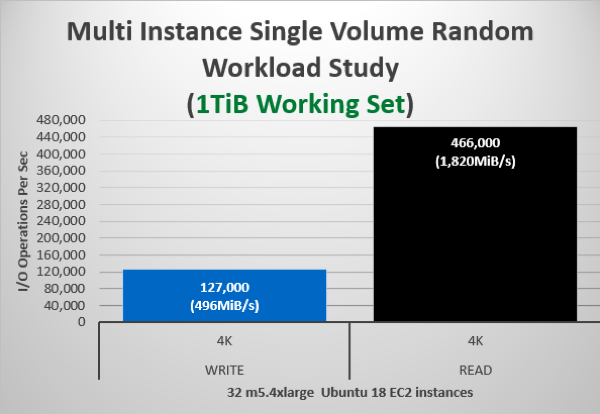
Random Scale Out Workload Study
Our study showed that working set sizes tend to have less of an impact on random workloads; thus, the following table illustrates data captured in the 1TiB test alone. A single volume can sustain up to ~470,000 random read IOPS or 130,000 random write IOPS (according to our test).
To achieve the above numbers, we used:
4KiB Read Workload

4KiB Write Workload (812MiB/s)

Scale Up (Single Instance) Workload Study
When it comes to scale-up performance, NetApp is quite happy to announce an exciting new development: though currently available only in the SUSE Linux Enterprise Server (SLES15), support for the nconnect NFS mount option has entered General Availability in the Linux 5.3 kernel. We anticipate that this support will be backported into forthcoming RHEL distributions. As documented by suse.com, the nconnect mount option requests multiple transport connections between the client and the storage IP. With this development in place, the I/O from even a single mount point is parallelizable across up to 16 network flows.
Please be aware: although the documentation (see item 4.6.2 in documentation for further information) calls out nconnect as a workaround for NFSv4 performance regressions, the new capability in Cloud Volumes Service works very well with NFSv3.
Amazon Network Architectural Discussion:
Amazon provides various amounts of bandwidth to an EC2 instance depending on virtual machine placements (in other words, depending on whether it is inside or outside of a cluster placement group). Cluster placement groups do not cross availability zones.
If the Instance is Part of a Cluster Placement Group
- Within a cluster placement group, EC2-to-EC2 communication has 10Gib/s of full-duplex bandwidth per network flow. A network flow is defined as Source IP (port):Destination IP (port).
If the Instance is Not Part of a Cluster Placement Group
- When the network flow is between an EC2 instance and a device not included in the placement group, the flow is allotted 5Gib/s of full-duplex bandwidth.
The FIO results captured against a single m5.24xlarge instance are presented in the charts below. The m5.24xlarge instance has about 25Gib/s of network bandwidth. Because the Cloud Volumes Service provides a single storage endpoint for each region, nconnect greatly increases the scalability of NFS for each individual EC2 instance. 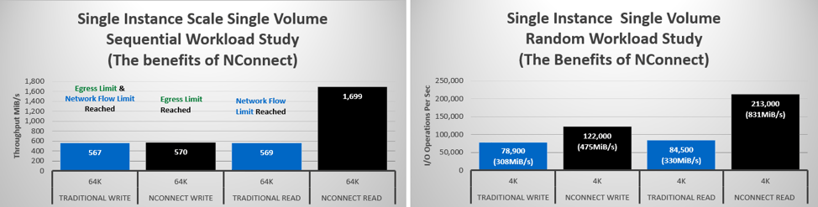
Methodology and Testing Tool
A synthetic workload generator, often called a benchmarking tool, is a tool used to generate and measure storage performance. Simplicity and scalability are two primary reasons that we use a synthetic generator instead of setting up and testing the actual application. Recently, FIO has become the tool of choice for this set of benchmarks. Advantageously, FIO is easy to obtain, simple to use, viable for both Linux (scale up and scale out) and Windows (scale up only) and supports asynchronous I/O to mimic real world applications.
FIO makes testing, in other words, quite quick and easy: load extremes can be evaluated without too much hassle. For reference, the strengths that we look for in a good generator are (in a nutshell):
- The ability to scale out a workload from one to many machines
- Incremental readouts showing the status of the test throughout the run
- The use of variable workload profiles to mimic things like logging in one stream and database reads and writes in another
- The ability to select an I/O engine to matching the paradigm of the application
Asynchronous I/O Support
Many modern enterprise applications support asynchronous I/O, including SAP, Oracle, MySQL, SQL Server, Postgres, Splunk, and Hadoop.
Beyond matching the needs of real-world modern applications, FIO’s use of asynchronous I/O allows the generator to avoid serialization. As such, it can better leverage compute cores on each virtual machine, which in turn drives the workload.
Test Plan
Our plan was to evaluate “the four corners” of storage by analyzing the upper limits of both large sequential throughput and small random I/O. Applications that need large sequential throughput include analytics, such as Hadoop, and MapReduce; workloads that require small random I/O include OLTP databases.
Cloud Volumes Service for AWS Topology
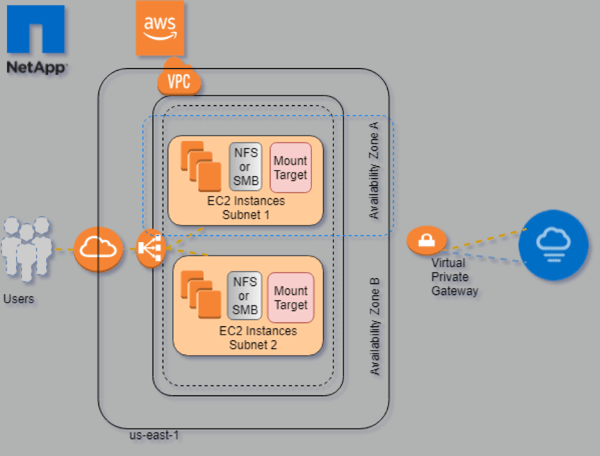
Running the Test
Running the Test
In our tests, we used the FIO load generator in addition to 32 m5.4xlarge virtual machines (for scale out) and 1 m5.24xlarge (for scale up). That allowed us to explore the amount of bandwidth available to a volume.
Our selection of the m5.4xlarge instance type was based on the 5Gbps of network bandwidth (burstable to 10Gib/s) available to the instance; the m5.24xlarge instance type was selected to demonstrate the additional bandwidth available by way of nconnect.
In each test, descending FIO iodepth values were selected {200,100,64,32,8,4,2,1} and the highest resulting figure selected for presentation.
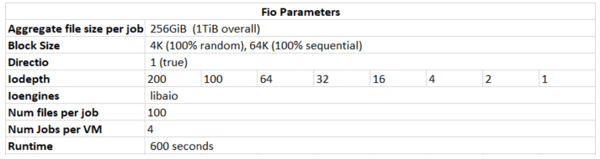
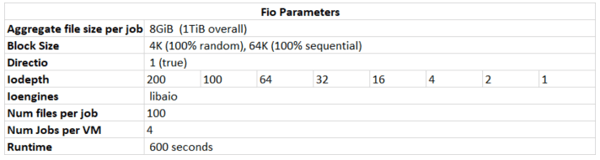
Except for the average aggregate file size (8GiB scale out and 256GiB scale up), all FIO parameters were maintained during both scale out and up. With four jobs per virtual machine in each test, 256GiB file sets (scale up) and 8GiB file sets (scale out), all tests used a 1TiB working set.
Note: Each section below includes a table documenting the FIO parameters used in each scenario.
Use the following script to parse the results of FIO runs:
Scale Up Single Instance Testing
Scale Out Multiple Instance Testing
Full instructions for running FIO may be found here:
https://github.com/mchad1/fio-parser/blob/master/how-to-run-fio
https://github.com/mchad1/fio-parser.git
Want to Optimize Your Performance with NetApp Cloud Volumes Service?
Request a demo from a NetApp cloud specialist today.