Share
Today, organizations are collecting data at a record pace. From sensor measurements to consumer behavior, the volume of data is growing exponentially and with that, the need for tools focused on big data and analytics. Such tools are immensely beneficial, for example, with Google Cloud databases.
Good tools and solutions that enable us to store and swiftly analyze large amounts of data make a tremendous difference in the day to day, ensuring that we can make the most out of our datasets and enabling data-driven decision making. Google Cloud offers this capability in Google Cloud BigQuery.
This post takes a closer look at this big data utility from Google Cloud and how to use it.
To jump down to the how-to, use this link How to Use Google BigQuery
What Is Google BigQuery?
BigQuery is a fully managed and serverless data warehouse solution available in the Google Cloud Platform that gives anyone the capability to analyze terabytes of data in a matter of seconds.
The Google BigQuery architecture is based on Dremel, a distributed system created by Google to query large datasets, however, that’s just scratching the surface of what’s going on with BigQuery. Dremel divides the query execution into slots, enabling fairness when multiple users are querying data simultaneously. Under the hood, Dremel relies on Jupiter, Google’s internal data center network, to access the data storage, on the distributed file system, codenamed Colossus. Colossus handles the data replication, recovery, and distribution management.
BigQuery stores data in a columnar format, achieving a high compression ratio and scan throughput. However, you can also use BigQuery with data stored in other Google Cloud services such as BigTable, Cloud Storage, Cloud SQL and Google Drive.
With this architecture tailored for big data, BigQuery works best when it has several petabytes of data to analyze. The use cases most suited for BigQuery are the ones where humans need to perform interactive ad-hoc queries of read-only datasets. Typically, BigQuery is used at the end of the Big Data ETL pipeline on top of processed data or in scenarios where complex analytical queries to a relational database take several seconds. Because it has a built-in cache, BigQuery works really well in cases where the data does not change often. In addition, cases where datasets are fairly small don’t really benefit from BigQuery, with a simple query taking up to a few seconds. As such, it shouldn't be used as a regular OLTP (Online Transaction Processing) database. BigQuery is really meant and suited for BIG data and analytics.
As a fully managed service, it works out of the box without the need to install, configure and operate any infrastructure. Customers are simply charged based on the queries they make, and the volume of data stored. However, being a black box has its disadvantages since you have very little control to where and how your data is stored and processed.
A key limitation and drawback is that BigQuery only works with data stored within Google Cloud and using their own storage services. Therefore, it’s not advisable to use it as the primary data storage location since that limits future architecture scenarios. It is then preferable to keep the raw dataset elsewhere and use a copy in BigQuery for analytics.
How to Use Google BigQuery
BigQuery is available in Google Cloud Platform. GCP customers can easily access the service from their familiar web interface console. In addition to the UI Console, Google BigQuery APIs can be accessed using the existing GCP SDKs and CLI tools.
Getting started with Google Cloud BigQuery is fairly simple and straightforward. You can get up and running very quickly using any dataset in a common format such as CSV, Parquet, ORC, Avro, or JSON. If you don’t have any data in mind to use for Google BigQuery, datasets are freely available to be explored and used in Google Cloud Public Datasets.
One example of a public dataset is the Coronavirus Data in the European Union Open Data Portal. It contains data related to the COVID-19 cases worldwide and can be used free of charge. Below, we are going to walk you through the steps to explore and analyze this dataset using Google BigQuery.
Step 1: Download the Dataset to your Computer
To get started, download the latest version of the dataset (in CSV format) to your local machine.
Step 2: Uploading and Storing the Dataset in Google BigQuery
1. In the Google Cloud Platform, navigate to the Google BigQuery Console under the Big Data section.
2. Find the “CREATE DATASET” button on the right-side panel and initiate the creation process. Give the dataset a unique identifier and select the geographical location to store and process the data. Save it using the button at the bottom of the panel.
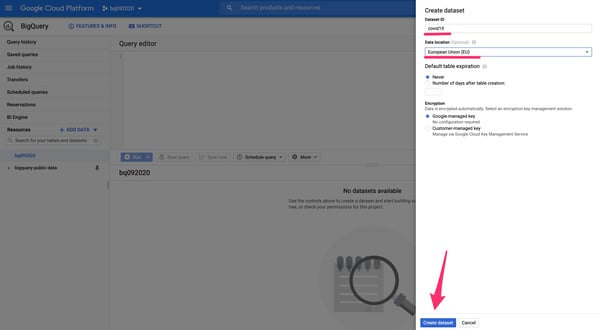 Database creation panel of a new BigQuery Dataset.
Database creation panel of a new BigQuery Dataset.
3. Select the newly created dataset and press the CREATE TABLE button. Use Upload as the source method, CSV as the file format, and select the local dataset file from your machine. Give it a table name (e.g. worldwide_cases) and select the Auto Detect option for the schema. Save it using the button at the bottom of the panel.
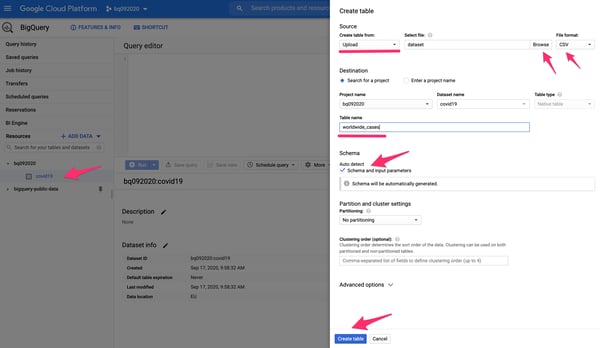 Table creation panel of a new BigQuery Dataset.
Table creation panel of a new BigQuery Dataset.
Step 3: Using BigQuery to Query Data Stored in Google BigQuery
With the dataset uploaded and stored in BigQuery, you will be able to start immediately querying the data using standard SQL.
1. In the panel, try a simple query such as SELECT * FROM `bq092020.covid19.worldwide_cases` LIMIT 1000 to retrieve up to a thousand rows.
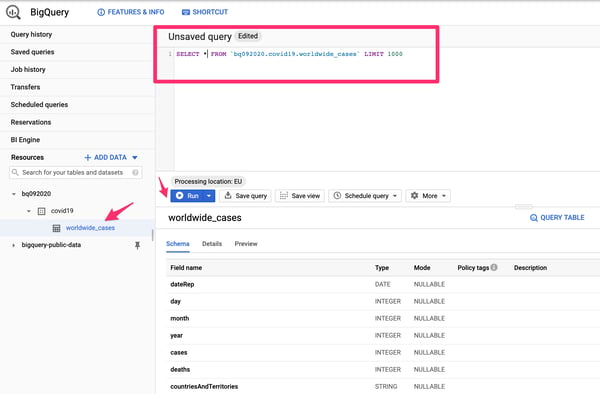 Simple query using the Google BigQuery interface.
Simple query using the Google BigQuery interface.
2. BigQuery Analytics are quite powerful. The interface gives access to full-fledged SQL capabilities, therefore you can use a more advanced query such as SELECT countriesAndTerritories, sum(cases) AS N_Cases, sum(deaths) AS N_Deaths, count(*) AS N_Rows
FROM `bq092020.covid19.worldwide_cases`
GROUP BY countriesAndTerritories
LIMIT 1000
3. Running the query above will provide aggregated results the Number of Cases and Deaths per Country/Territory.
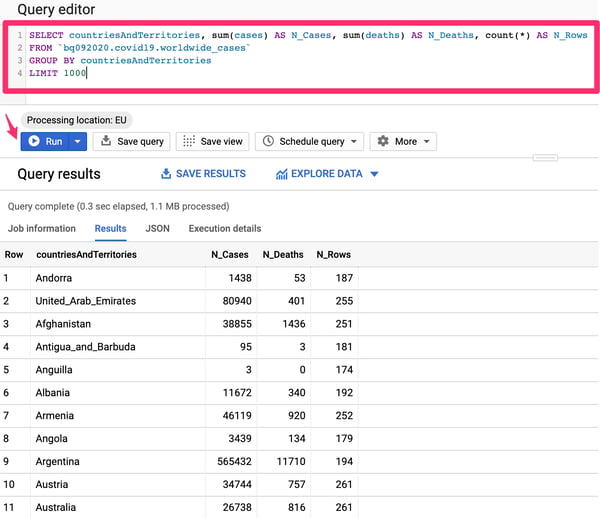 Aggregated Query results using the Google BigQuery interface.
Aggregated Query results using the Google BigQuery interface.
Step 4: Adding the Dataset to Google Cloud Storage
Since Google BigQuery supports some external data sources, we can achieve similar results and capabilities using Google Cloud Storage as a data storage for the dataset file.
Creating a new Google Cloud Storage bucket and uploading the dataset file can be done rather simply. If you haven’t done one yet, you can learn how to create a bucket here.
Step 5. Using BigQuery with a Dataset in Google Cloud Storage
1. Create a new table under your BigQuery dataset and select Google Cloud Storage as the source. Fill in the GCS bucket name and file location with CSV as the format. Give it a different name from the previous created table (e.g.: worldwide_cases_in_bucket).
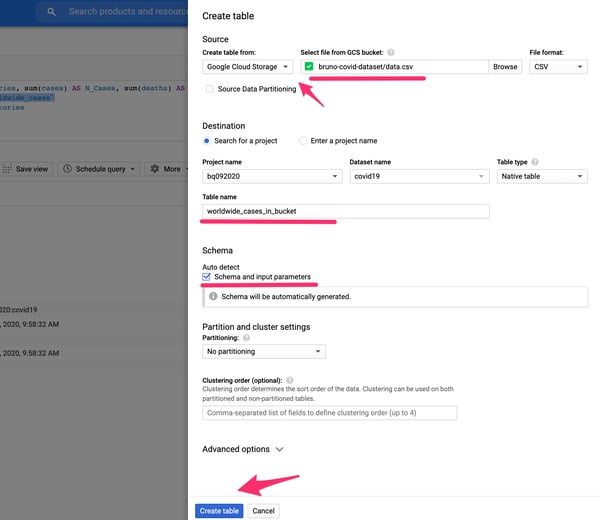 Creating a table from an external data source in Google BigQuery
Creating a table from an external data source in Google BigQuery
2. The newly created table will be immediately able in the interface. The data can be queried in the exact same manner as any other data stored in BigQuery. To test it, try using the same aggregation query by simply updating the FROM clause with the new table name.
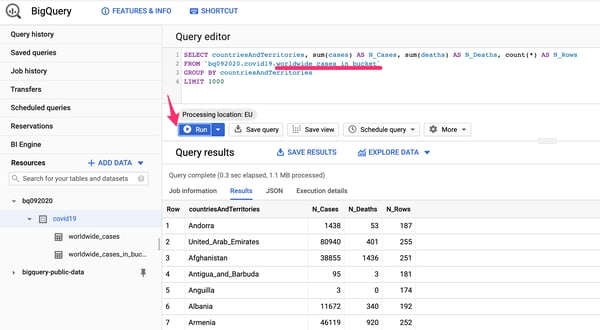 Using BigQuery to query data stored in an external data source.
Using BigQuery to query data stored in an external data source.
Conclusion
As you just saw, BigQuery is incredibly powerful in enabling data exploration and analysis capabilities from zero to hero without much effort. In a world where data acquisition is growing at an astonishing rate, tools like BigQuery help to generate value out of data.
However, despite its unique advantages and powerful features, BigQuery is not a silver bullet. It is not recommended to use it on data that changes too often and, due to its storage location bound to Google’s own services and processing limitations it’s best not to use it as a primary data storage.
For customers looking to store large amounts of data, Cloud Volumes ONTAP, the data management platform from NetApp, is a great option to consider. Available in AWS, Google Cloud and Azure, it enables customers to keep their options open in how and where their data is stored and processed. Cloud Volumes ONTAP is perfect for Big Data solutions, providing customers advanced features such as cost-cutting storage efficiency, cloning, data tiering and protection, while helping to reduce the expense of high performance storage by as much as 70% in some cases.

