Share
As cloud adoption matures across organizations of all sizes, IT teams face a new challenge: how to monitor and optimize resource usage across a multitude of environments. The problem might be less acute if IT were less complex and fragmented. But the reality is that hybrid and multicloud infrastructures are the norm, and those infrastructures, as well as the workloads that run on them, typically require a diverse suite of monitoring tools to manage.
If you’re already a Cloud Insights user, or are just getting started with a free trial, this blog will take you through some features you can use in your own environment to get a deeper insight into how your environment is performing, and where there are opportunities to optimize.
Data Collection Has Never Been Easier
To start collecting data from infrastructure resources in your environment, you simply need to configure an Acquisition Unit (AU) and you’re ready to go. However, you can even get started without an AU by adding Cloud Insights’ Telegraf agents to hosts as a way to collect host and service metrics. Installing and configuring Acquisition Units and Agents is a straightforward procedure. Each Acquisition Unit can host multiple Collectors that acquire and send resource, host, or service metrics to Cloud Insights for infrastructure monitoring and analysis.
Here’s how easy it is to add a new Data Collector to Cloud Insights:
1. Click the +DataCollector button and choose the type of Data Collector (Operating Systems, Services, or Infrastructure). The figure below shows a sample infrastructure Data Collector dialog box for an Azure Compute resource.
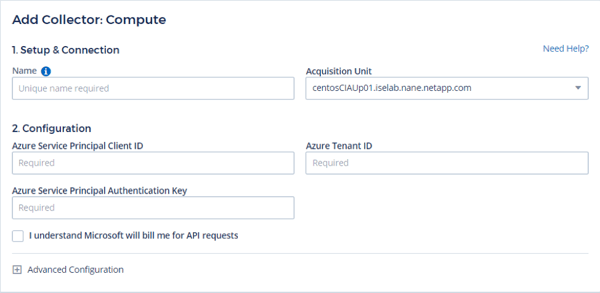 Figure 1: Adding an Azure Compute Collector
Figure 1: Adding an Azure Compute Collector
2. In the 1. Setup & Connection field, provide a unique Collector name, which is generally the host or service name of the resource in question, and specify the Acquisition Unit that will do the collection. Note that you can configure multiple Acquisition Units for your environment, which can be very useful when resources are spread across multiple geographic locations and clouds. If you’re only using one Acquisition Unit in your environment, the one that you set up when you initially configured your Cloud Insights tenant will be selected.
3. In the 2. Configuration field, provide credentials that are relevant to the specific Collector type. In this case, the relevant credentials are the Principal Client ID, Tenant ID, and Principal Authentication Key. The credentials are stored read-only and encrypted in the Acquisition Unit, and are accessible only through the encryption key on the Acquisition Unit itself, which is always entirely and solely under user control.
4. You also have the option to provide additional configuration information to alter the default behavior; below, you can see how to alter the default collection intervals, or to filter out certain tags from the collection process.
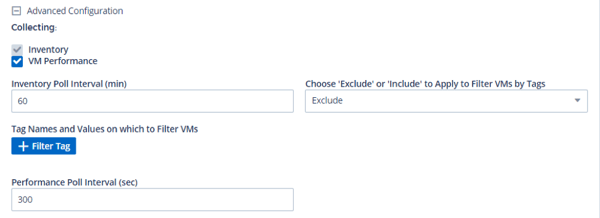 Figure 2: Advanced configuration parameters for an Azure Compute Data Collector
Figure 2: Advanced configuration parameters for an Azure Compute Data Collector
5. When done, click Test Configuration at the bottom of the page to verify that the connection is viable and Add Collector to close the transaction—and you’re ready to go.
You can install a host agent from the same page, where you can copy and paste and installation string to the server you want to monitor. You need to specify an Access Key for the Agent, rather than an Acquisition Unit. Access Keys are tokens that both allow the Collectors to report back directly to Cloud Insights, and allow Collectors to be enabled or disabled as groups. Services for which Data Collectors are available are CouchDB, Docker, Elasticsearch, Hadoop, Kubernetes, PostgreSQL, Puppet, and Redis—to name just a few.
Actionable, Visual Troubleshooting
As a part of this infrastructure monitoring tool, Cloud Insights uses dashboards and policy-based alerts to help IT teams quickly see and respond to issues in the environment—hopefully before end users are even aware that there’s a problem.
Dashboards
Dashboards are important visualization tools for cloud monitoring. Cloud Insights comes with a number of out-of-the-box dashboards that present operational views of the collected data. These dashboards are a great starting point to copy and adjust to make your own, and you can also create them from scratch, which isn’t as ominous as it sounds. Cloud Insights’ dashboards turn tedious, manual troubleshooting tasks into information at your fingertips.
A Cloud Insights dashboard is a collection of widgets. Building a widget is simple: you pick a visualization style, an asset type to display, and then define filters and finders to narrow down the data you can see. The widgets that can be incorporated into a Cloud Insights dashboard include tables, time-series charts, single values (either direct or calculated), bar/column charts, scatter plots, pie charts, free text notes, and violations tables. You use queries and filters to determine which data will be displayed by default in a widget and to apply a data rollup or aggregation method such as average, maximum, minimum, or sum. Some widget types support multiple queries. You can also set a default time range selector for the dashboard as a whole, which can be overridden on a widget-by-widget basis.
The following dashboard, for example, incorporates several widget types to provide a clear operational view for VMware admins. It reveals which VMs are experiencing the highest latency.
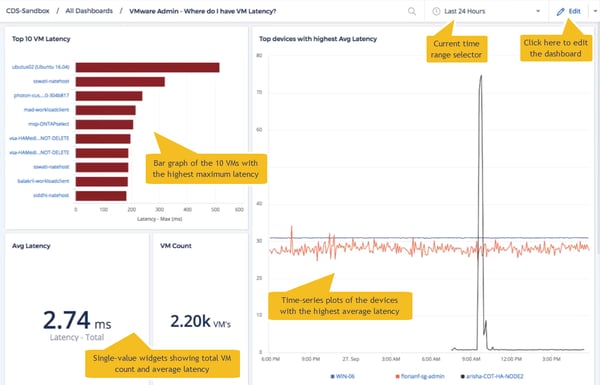 Figure 3: Dashboard showing where the system is experiencing high VM latency
Figure 3: Dashboard showing where the system is experiencing high VM latency
Asset Landing Pages
If the dashboard indicates that a particular VM is problematic, you can drill down to its detailed asset landing page as shown in Figure 4. You can also click View Topology on the landing page to see the resource’s full operational context as shown in Figure 5, as well as compare the performance metrics of correlated resources, as shown in Figure 6.
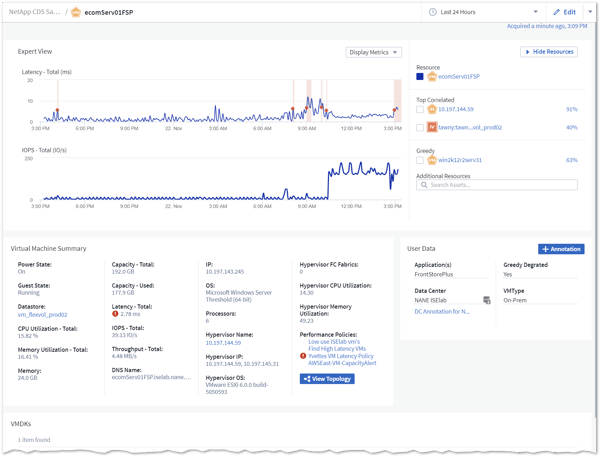 Figure 4: Partial view of an Asset landing page for a specific VM
Figure 4: Partial view of an Asset landing page for a specific VM
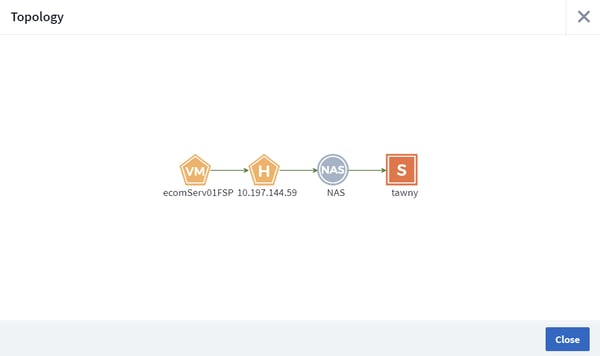 Figure 5: The full operational context of the VM
Figure 5: The full operational context of the VM
Cloud Insights uses machine learning to determine other resources that are most closely correlated with the VM, and their graphs can be displayed together with the VMs (see Figure 6) in order to better understand how other resources in the system are affecting the latency of the VM in question.
 Figure 6: Overlaid correlated IOPS graphs
Figure 6: Overlaid correlated IOPS graphs
Performance Policies and Alerts
Alert fatigue is a well-known malady among those tasked with monitoring and troubleshooting infrastructure performance. Cloud Insights addresses this issue by letting you define performance policies (see Figure 8) to apply to generic asset types. This means you can define universal thresholds for a “Virtual Machine” asset, and those policies will create alerts for workloads whether they’re in the cloud or on premises, across a multitude of different platforms including GCP, AWS, Azure, VMware, Openstack, and Hyper-V.
By default, a performance policy applies to all the resources of that type, but you can use annotations to apply the performance policy to a specific asset or set of assets. For instance, you may want to define a different threshold for resources tagged as QA or Dev than those tagged as Production.