Share
AWS provides block, file, and object storage for use cases ranging from DevOps and data analytics to disaster recovery and backup. Which is right for you? Understanding the SLA differences between Amazon EBS, Amazon EFS, and Amazon S3 storage is a key business decision.
In this blog, we will talk about SLAs for various AWS storage services — Amazon EBS vs. S3 vs. Glacier and more — mainly in terms of durability and availability. We’ll also show you how NetApp’s Cloud Volumes ONTAP can help you make more cost-effective use of AWS SLA-based storage.
Availability and Durability
These two terms can often be confused, but they are both important parts when it comes to choosing storage services and understanding tradeoffs, such as price for redundancy.
Availability is more geared towards hardware redundancy while durability is more about data redundancy. Data availability is mainly achieved through RAID or erasure coding (where the data is broken into fragments, sharded and distributed across a storage pool); you would notice the SLAs align with the SLAs possible through those technologies. To view this in terms of number of hours: 99.99% SLA translates to 8h 45m 57s and 43m 49.7s of potential downtime in an annual and monthly time period, respectively.
Durability is about the ability for data to be protected from corruption and bit rot over the long term. RAID is not impervious to data degradation like bit rot. In these scenarios, a combination of erasure coding and data scrubbing (where the data is continuously validated) can help provide durability of up to Eleven 9s in some AWS storage services.
When choosing storage systems, both durability and availability should be taken into account.
AWS SLA Comparison
In this section we’ll compare the different SLAs of Amazon S3, Amazon Glacier, Amazon EFS, Amazon EBS, and Amazon EC2 Instance Store.
Amazon S3
Let’s start with AWS’s most popular object storage: Amazon S3. Both Amazon S3 Standard storage and Standard-IA storage can automatically store and sync data across devices and locations within AWS regions, providing excellent durability and availability levels.
With Amazon S3 there are absolutely zero points of failure, as it comes with built-in error correction. As it’s designed to handle a loss of two redundant storage facilities, Amazon S3 makes for a good choice to serve as primary storage for the most critical data. This storage format comes with what’s called “Eleven 9s” of durability, as it’s 99.999999999 percent durability per object. It also has a 99.99% availability per year.  The difference between Amazon S3 Standard and Standard-IA is one of those nines: Standard boasts 99.99% availability per year and Standard-IA 99.9% per year.
The difference between Amazon S3 Standard and Standard-IA is one of those nines: Standard boasts 99.99% availability per year and Standard-IA 99.9% per year.
Cross-region replication is another factor to consider in Amazon S3’s SLAs. With cross-region replication, copies of Amazon S3 buckets are created automatically and asynchronously in multiple AWS Regions.
If these AWS SLA standards are not met, you can request service credits from AWS before the end of the second billing cycle from the incident occurrence.
Another low-redundancy option of this storage class is Amazon S3 Reduced Redundancy Storage, or RRS. Although this storage has the same availability SLA of 99.99% as Amazon S3 Standard Storage, it has a much lower durability of 99.99% (as compared to Eleven 9s in Standard). Although, this storage option provides 400 times the durability of a normal disk drive, it allows the data to reside in a single facility as compared to two facilities as in Amazon S3 Standard and Standard-IA Storage.
Amazon Glacier
What’s the difference between S3 and Glacier? Technically, they are part of the same service. While Glacier was originally planned to be a stand alone storage offering for archival data, it was eventually classed as a storage class of Amazon S3.
So, how does Amazon Glacier vs S3 stack up? Amazon Glacier storage is geared more towards durability than availability. This low-cost storage is used mainly for data backup and archival. Amazon Glacier deals Eleven 9s of durability per year best suited for archival data. This service redundantly stores data in multiple data centers and on multiple devices in each data center, which allows that durability. In this case, the difference between S3 and Glacier comes down to which storage class of S3 you are planning to use.
Unlike traditional systems, this data is stored synchronously and there are built-in, self-healing technologies that bypass expensive and labor-intensive data verification and manual repair procedures.
Amazon EFS
AWS EFS is a highly-durable and highly-available file-storage service that is fully managed by AWS. Amazon EFS is distributed across unconstrained number of storage servers which allows the data to scale up to the petabyte level and allows parallel access to Amazon EC2 instances. All Amazon EFS objects are stored in more than one AZ.
Unlike the various SLA guarantees AWS gives for Amazon S3, the exact levels of durability and availability for Amazon EFS are not specifically stated, though it has been designed to match all of Amazon S3’s benchmarks.
Amazon EBS
AWS EBS volumes provide persistent block storage with high availability for Amazon EC2 instances. Data stored in these volumes is replicated in multiple servers within one AZ, which keeps data from being lost should a single repository fail.
Amazon EBS volumes have annual failure rates that range between 0.1% - 0.2% every year. Translation: for every 1000 Amazon EBS volumes that you provision in a year, you can expect just one or two of them to fail. Amazon EBS volumes provide an availability of 99.999%. Although Amazon EBS Volumes have a low rate of failure and high availability, it is recommended to create frequent snapshots.
This ensures that even if the volume is unavailable, it can be recreated from the most recent snapshot. However, Amazon EBS costs for snapshots should also be kept in mind.
Amazon EBS Durability
Amazon EBS durability is 20 times higher than on typical commodity disk drives. Only one or two Amazon EBS volumes could fail among thousands of volumes in a single year, an annual failure rate is between 0.1% and 0.2%, which covers events where failure is complete or partial. While this isn’t as close to the durability that comes with Amazon S3 or Glacier, it still ranks as exceptionally high.
To help with Amazon EBS durability, volumes have the ability to create snapshots for point-in-time backups. When you restore Amazon EBS volume data from snapshots, a volume is created and the data is made available in the same moment, with no need to wait for the data to be copied to new volume. Also, when restoring a volume from a snapshot, the size of new volume can be larger than the original volume. Snapshots can also be shared to other users or copied across different AWS regions, granting additional levels of EBS durability.
Amazon EC2 Instance Store
Amazon EC2 Instance Store (also known as ephemeral drives) provide temporary block-level storage for many Amazon EC2 instances. These instance stores are normally pre-configured block storage present on the same physical host that is hosting the Amazon EC2 instance.
These drives are not meant to be durable as the data is persistent only for the duration of the associated Amazon EC2 instance; as such, should an Amazon EC2 instance stop or fail for whatever reason, then all the instance store data will not be able to be retrieved.
Here is a summary of all the persistent storage types on AWS and their SLAs: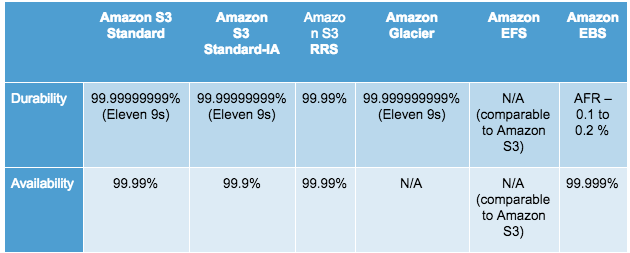
NetApp Cloud Volumes ONTAP on AWS
Imagine you want to make use of Amazon EBS for its performance and availability, but storing all your data in Amazon EBS storage can be a little pricey. NetApp’s Cloud Volumes ONTAP enterprise data management software has a number of features that help save costs when seeking the best AWS SLAs.
What happens when that slight chance that AWS storage system fails? With Cloud Volumes ONTAP configured for high availability, you stay protected from unexpected disk failures, as two Cloud Volumes ONTAP instance nodes are in place to make sure that RTOs of under 60 seconds are met without data loss (RPO=0), failover and failback are seamless, and synchronous mirroring allows for transparent self-healing.
Also, creating Cloud Volumes ONTAP snapshots and data replication to secondary sites are easy to make happen with simple drag-and-drop controls. In just a few clicks Cloud Volumes ONTAP helps give you a complete and up-to-date DR site running in the cloud in a cross-zone or cross-region mode. And how can you best take advantage of AWS SLAs while managing costs?
And how can you best take advantage of AWS SLAs while managing costs?
As part of Cloud Volumes ONTAP’s AWS disaster recovery solution, data tiering can automatically store infrequently-accessed data in less-expensive Amazon S3 bucket and automatically move that data back to Amazon EBS volumes as and when it is needed.
Data tiering can also be used to tier snapshot data to Amazon S3. Using this feature, storage costs can be as low as $0.03 per month. In addition to this, Cloud Volumes ONTAP also provides a number of cost-saving storage efficiencies such as thin provisioning, data deduplication, data compression, and data cloning.
These storage efficiency features can lower your overall AWS storage costs by as much as 50% or even 70%, in some cases.To see more about how Cloud Volumes ONTAP works with different AWS SLAs, check out NetApp’s AWS calculator, which can help you calculate the TCO for Cloud Volumes ONTAP running on AWS storage. Apart from DR and data tiering, Cloud Volumes ONTAP also serves a wide range of other use cases such as lift-and-shift migrations of existing applications and provisioning clones for DevOps test and staging environments.
Final Note on AWS SLAs
There are a lot of differences when it comes to comparing in Amazon EFS vs. EBS vs. S3 vs. Glacier. While it is important to consider the cost of storage, storage service SLA is also necessary to keep in mind as unplanned downtime can impact your organization. This is the reason it is important to check the case studies of organizations that have already deployed these solutions.
Finally, it is important to understand the use of lifecycle management of AWS objects so that your data which is not accessed frequently but needs to archived can be moved to more inexpensive solutions such as Amazon Glacier.
