Share
In Kubernetes storage, persistent volumes are used to provision storage for containerized applications and provide a separation between how storage is used and how it is allocated. However, there’s a catch. Storage, especially in large allocations, is expensive.
Cloud Volumes ONTAP can deliver enterprise-grade storage efficiencies that will considerably improve the cost effectiveness of your Kubernetes persistent storage in the cloud.
Read on as we cover:
- Persistent Volumes in Kubernetes
- Reducing Kubernetes Cloud Storage Costs with Cloud Volumes ONTAP
- The Easy Way to Pay Less for Persistent Storage
The Costs of Persistent Volumes in Kubernetes
Persistent volumes can be either created manually ahead of time, a process known as static provisioning, or automatically created in response to incoming persistent volume claims, which is known as dynamic provisioning. In both cases, it can be a challenge to ensure storage efficiency. There are a number of downsides to inefficient storage usage:
- Overprovisioning: Aas application developers must prepare for storage usage peaks, they and can often overestimate the amount of storage that they need. In a cloud environment, this leads to an unnecessary increase in cloud storage costs.
- Cold Data: There may also be situations where a large part of the production data set is cold, or infrequently accessed, but which cannot be moved to more cost-effective storage without introducing a lot of complexity to the ways application services rely on that data. These application services require a uniform view of their data, with fast access to hot data and on-demand access to cold data. This can again be a difficult problem to solve, resulting in large allocations of high performance and costly storage.
- Complexity: Another scenario where transparently-applied storage efficiency would hold great value is where the data being stored contains a high degree of redundancy, which could be compressed in order to reduce the overall amount of storage required. Moving the onus for compression to the storage layer simplifies application software development and also helps to reduce the cloud storage footprint of legacy and third-party application services, where changes to the systems cannot be made.
- Higher Costs: The common denominator of all the points mentioned above are the increased costs of inefficient storage usage. In enterprise deployments, where persistent data sets have the potential to take up enormous amounts of space, that can be a matter of thousands of dollars per month.
Though storage efficiency is always important in the cloud, it can be even more so in Kubernetes environments due to the inherent scalability of containers. Spinning up new pods to deal with an increase in workload, or to provide greater redundancy and availability, also requires allocating new persistent volumes. The storage overhead for these persistent volumes can be brought under control through efficient data storage.
Reducing Kubernetes Cloud Storage Costs with Cloud Volumes ONTAP
Kubernetes benefits from NetApp Trident by being able to directly take advantage of NetApp’s enterprise-grade data storage management platform. By way of dynamic provisioning, Trident will automatically create storage volumes in Cloud Volumes ONTAP using AWS storage or Azure storage, or any on-premises ONTAP system. Besides the added benefits of FlexClone® instant, writable clones and enhanced data protection for Kubernetes deployments, one of the primary reasons for using Trident is that it opens up the storage efficiency features of Cloud Volumes ONTAP, providing Kubernetes advantages in terms of transparently reducing the storage space required for persistent volumes.
Now let’s take a closer look at the efficiencies:
Thin Provisioning
Thin provisioning makes it possible to create persistent volumes that appear to pods as having the size they requested through a persistent volume claim, but without needing to allocate all of that storage in advance. Cloud Volumes ONTAP will automatically add storage capacity to the persistent volume as and when it is required, and also return back freed up storage to the common pool when data is deleted. This ensures that storage space is only allocated when it’s actually needed, which reduce storage usage costs and drives up storage space utilization. Thin provisioning also makes it much easier to plan for the future storage requirements of the cluster.
Data Deduplication
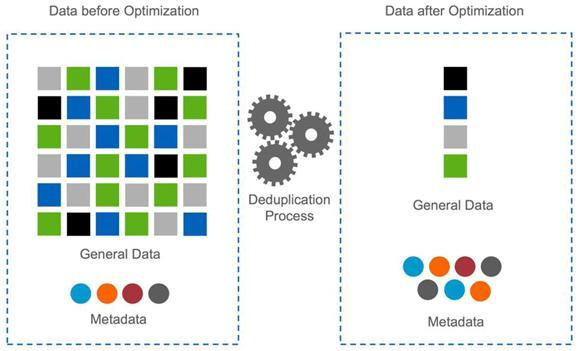
 Cloud Volumes ONTAP is able to transparently apply transformations, which help to reduce storage space usage, to the data it stores. Data deduplication collapses identical copies of a block into a single block, with reference pointers inserted into every place the block is used. This can dramatically reduce storage space requirements, with some customers reporting savings of up to 70%. A small amount of storage space is consumed in order to maintain the metadata required to support the block mappings.
Cloud Volumes ONTAP is able to transparently apply transformations, which help to reduce storage space usage, to the data it stores. Data deduplication collapses identical copies of a block into a single block, with reference pointers inserted into every place the block is used. This can dramatically reduce storage space requirements, with some customers reporting savings of up to 70%. A small amount of storage space is consumed in order to maintain the metadata required to support the block mappings.
Data Compression
Data in an ONTAP storage volume can be transparently compressed without requiring any changes to client applications and services. This compression is applied to groups of consecutive blocks, as opposed to entire files, which makes reading and updating highly optimal. Data compression can also be used in conjunction with data deduplication.
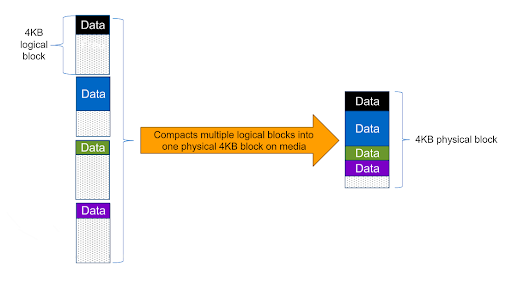
Data Compaction
NetApp is constantly innovating and extending the capabilities of the ONTAP platform, and data compaction is one of the more recent features to be introduced. After applying inline data deduplication and compression, multiple blocks that are not completely filled are combined together, removing the unused of space that would have otherwise been left in each block.
Storage Tiering
A major advantage of using Cloud Volumes ONTAP is the ability to automatically balance data between a capacity storage tier for colder data and a performance tier for fast access. Depending on the cloud vendor being used, Cloud Volumes ONTAP will use Amazon S3 or Azure Blob for the capacity tier, which provides significant cost savings for large amounts of data that are infrequently accessed, but that must still be available on-demand. When the data is required, it is transparently moved to the performance tier, and will age back out to the capacity tier when it is no longer in active use.
Cloud Volumes ONTAP customers such as Concerto Cloud Services and Reach PLC (formerly Trinity Mirror) are two examples of leveraging storage efficiencies to drastically lower TCO. Using the features covered above, Concerto managed a 96% reduction of storage footprint and Reach achieved a 50% storage reduction.
The Easy Way to Pay Less for Persistent Storage
Leveraging the flexibility of persistent volumes and dynamic provisioning, NetApp Trident acts as a gateway for Kubernetes clusters to take advantage of the mature and ever-evolving data storage management feature set of Cloud Volumes ONTAP. One of the most compelling arguments for choosing this solution is the wealth of storage efficiency technologies that are built into NetApp’s ONTAP storage services, which can be used transparently, and in combination with each other, to greatly reduce operational cloud storage costs.
Learn more about how Cloud Volumes ONTAP supports Kubernetes Persistent Volume provisioning and management requirements of containerized workloads, and how Cloud Volumes ONTAP helps to address the challenges of containerized applications in these Kubernetes Workloads with Cloud Volumes ONTAP Case Studies.

