- Product
- Resources
 LEARN
LEARN- Cloud Storage
- IaaS
- DevOps
 CALCULATORS
CALCULATORS- TCO Azure
- TCO AWS
- TCO Google Cloud
- TCO Cloud Tiering
- TCO Cloud Backup
- Cloud Volumes ONTAP Sizer
- Azure NetApp Files Performance
- Cloud Insights ROI Calculator
- AVS/ANF TCO Estimator
- GCVE/CVS TCO Estimator
- VMC+FSx for ONTAP
- NetApp Keystone STaaS Cost Calculator
 BENCHMARKS
BENCHMARKS- Azure NetApp Files
- CVS AWS
- CVS Google Cloud
- Blog
- AWS
- Azure
- Google Cloud
- Data Protection
- Kubernetes
- General


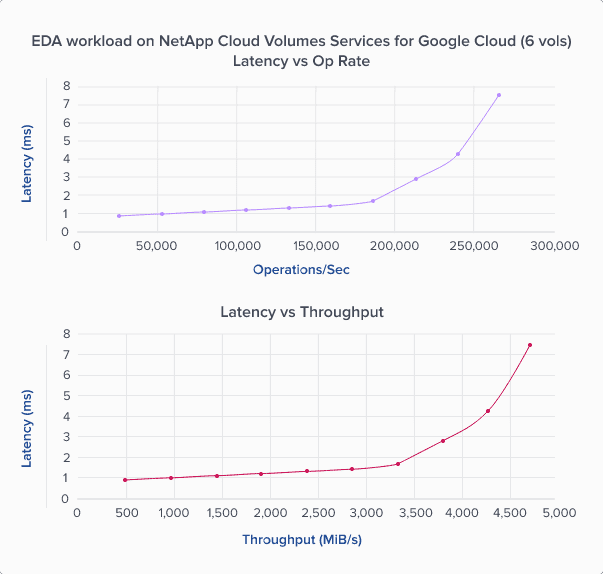
-Workload-Throughput.png?width=603&height=388&name=Linux-(Scale-Out)-Workload-Throughput.png)
-Workload%E2%80%93IOPS.png?width=603&height=388&name=1Linux-(Scale-Out)-Workload%E2%80%93IOPS.png)
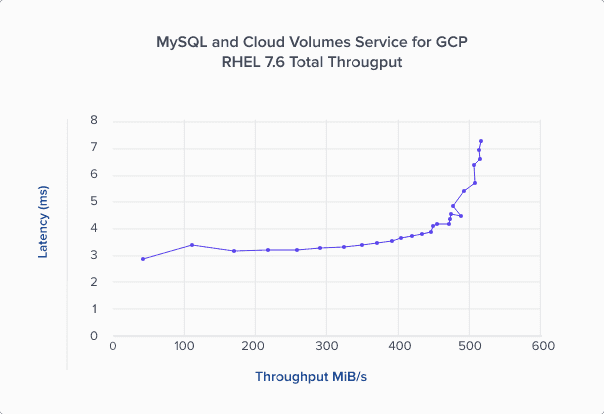
-Read-Throughput.png?width=537&height=388&name=Linux-(Scale-Up)-Read-Throughput.png)
-Write-Throughput2.png?width=537&height=388&name=Linux-(Scale-Up)-Write-Throughput2.png)