Share
What is Azure Big Data?
The Microsoft Azure cloud emphasizes AI and analytics services in its offering. This is a great option for those who want to combine the benefits of big data analytics with cloud computing. The Azure platform makes it easy to process structured and unstructured data in high volumes. It also comes with real-time analytics and a fully managed infrastructure that includes Azure database services, analytics services, machine learning and data engineering solutions.
This is part of an extensive series of guides about managed services.
In this article, you will learn:
- Big Data in Azure: Service Options
- Steps to Building a Big Data Solution on Azure
- Azure Big Data with NetApp Cloud Volumes ONTAP
Big Data in Azure: Use Cases
Azure provides a range of services that can help you set up a big data infrastructure, from databases, to data processing and analytics, to machine learning and integration of complex data sources.
Databases
Azure database options include self-managed Table Storage, self-managed databases hosted on a virtual machine, and managed databases such as SQL Server, PostgreSQL, MySQL, and MariaDB.
Related content: read our guides to Azure SQL database and Oracle on Azure
If you are interested in a fully managed service, you can use Cosmos DB by Azure. Cosmos is a scalable, flexible, low-latency service that supports global deployment and replication of multiple database engines. Its APIs are compatible with a wide range of tools, including MongoDB, Cassandra, Apache Spark, SQL, Jupyter Notebook, Table Storage, Gremlin, and more.
Azure also provides SQL Data Warehouse, for large scale structured data, and Azure Data Lake for unstructured data.
Analytics
Azure provides a wide variety of analytics products and services. Currently, the most popular services are HDInsight and Azure Analysis Services.
Analysis Services provides an enterprise-class analysis engine that can collect data from multiple sources and turn it into an easy-to-use semantic BI model. The service integrates predefined database models and can generate interactive dashboards and reports. There’s no need for writing code or managing data processing.
HDInsight is an enterprise service that focuses on open source analytics, and is compatible with popular platforms like Apache Hadoop, Spark, and Kafka. It integrates with Azure services like SQL Data Warehouse and Azure Data Lake, making it easy to create analytical pipelines. HDInsight can integrate with custom analysis tools, and supports many popular languages, such as Python, JavaScript, R, .NET, and Scala.
Machine Learning
Azure provides a variety of solutions for artificial intelligence and machine learning, including Azure Machine Learning Services (AMLS). AMLS lets you create customized machine learning models, using a zero-code drag and drop interface, as well as a code-first environment. It is compatible with open source tools and platforms such as PyTorch, TensorFlow, ONNX, and scikit-learn.
Azure Machine Learning Services helps automate machine learning with tools like automated feature selection, algorithm selection, and hyperparameter scanning.
Data Engineering
There are two main Azure services you can use to create complex data pipelines: Data Factory and Data Catalog.
Data Factory provides serverless integration for local and cloud-based data repositories. You can use Data Factory to perform extract, load, transform (ELT) or extract, transform, load (ETL), using more than 80 data connectors provided natively by Azure. You can accomplish this with or without scripts. It can be automated with scheduling, drag and drop wizards, or event-based triggers. You can integrate Data Factory with Azure Monitor, to gain visibility and manage the performance of data flowing through CI/CD pipelines.
Data Catalog comes as a fully managed offering for finding and understanding data sources. With Data Catalog, you can crowdsource metadata and annotations to users and let them share their knowledge. This makes data more easily searchable and accessible.
Steps to Building a Big Data Solution on Azure
Microsoft recommends a three-step process to building a new big data solution in the Azure cloud: evaluation, architecture, configuration, and production.
1. Evaluation
Before choosing a service, you need to evaluate your big data goals. You must understand the type of data you want to include and how to format it. For example, data from web scraping is very different from the data you get from an IoT sensor. The type and amount of data used will help you plan data ingestion and the type of storage required.
Once you know what data to process, you must decide how to analyze it. If your team doesn't have a data scientist, you can use one of the big data service options. In this case, it is better to add machine learning to the system based on specific skills. Also take into account your current machine learning tools and scripting languages.
If you are new to cloud services, you should familiarize yourself with the full scope of an Azure migration. Consider starting your project by migrating core applications and processes to the cloud, and only then migrating your big data itself. It is possible to leverage the cloud for big data processing and analysis even without migrating large-scale datasets.
2. Architecture
Suppose you want to create your own solution. Define an initial architecture based on the results of your evaluation. This architecture should depend on your legacy systems (if you have existing big data infrastructure in your local data center) and the skills of your development and operations teams. However, typical components of an architecture are shown below, and you can use them as a template for your individual setup.
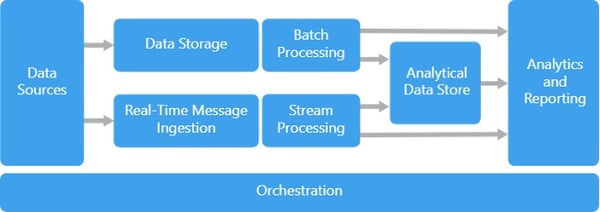
Source: Azure
3. Production
After selecting the services, you need, you can configure and prepare your production environment. Your exact configuration will depend on the services you choose, the combination of data sources, and whether you are creating a hybrid or pure cloud environment.
Whatever specific configuration you use, you should monitor as many processes as possible to get the best performance and the best return on your investment. Azure Monitor and Log Analytics can be of help. Define and enforce a policy for privacy and security, and consider backup, restore, and disaster recovery for your big data system.
Azure Big Data with NetApp Cloud Volumes ONTAP
NetApp Cloud Volumes ONTAP, the leading enterprise-grade storage management solution, delivers secure, proven storage management services on AWS, Azure and Google Cloud. Cloud Volumes ONTAP supports up to a capacity of 368TB, and supports various use cases such as file services, databases, DevOps or any other enterprise workload, with a strong set of features including high availability, data protection, storage efficiencies, Kubernetes integration, and more.
In particular, Cloud Volumes ONTAP helps in addressing database workloads challenges in the cloud, and filling the gap between your Azure database capabilities and the Azure resources it runs on.
Cloud Volumes ONTAP supports advanced features for managing SAN storage in the cloud, catering for NoSQL database systems, as well as NFS shares that can be accessed directly from cloud big data analytics clusters.
In addition, the built-in storage efficiency features, including thin provisioning, data compression, deduplication, and data tiering, reduce storage footprint and costs by up to 70%.

Azure Data Lake: 4 Building Blocks and Best Practices
Azure Data Lake is a big data solution based on multiple cloud services in the Microsoft Azure ecosystem. It allows organizations to ingest multiple data sets, including structured, unstructured, and semi-structured data, into an infinitely scalable data lake enabling storage, processing, and analytics. Learn about the 4 key components of an Azure Data Lake - core infrastructure, ADLS, ADLA, and HDInsights - and best practices to using them effectively.
Read more in Azure Data Lake: 4 Building Blocks and Best Practices.
Azure NoSQL: Types, Services, and a Quick Tutorial
NoSQL databases are non-relational databases that can flexibly support data. These databases are highly scalable and can be adapted to a wide variety of applications and workloads. This makes NoSQL databases popular alternatives to traditional databases and is driving robust support from cloud vendors like Azure. This article explains what Azure NoSQL services are available, highlights the APIs provided for Azure's main NoSQL database (CosmosDB), and provides a brief tutorial for deploying a NoSQL cluster.
Read more: Azure NoSQL: Types, Services, and a Quick Tutorial.
Azure Analytics Services: An In-Depth Look
Azure Analytics Services provide a wide range of capabilities that help organizations worldwide leverage their data. Notable examples are Azure Machine Learning and Azure Data Share, which help data collaborators simplify work with machine learning models and share their work.
Read more: Azure Analytics Services: An In-Depth Look.
Best practices to follow when using Azure HDInsight for Big Data & Analytics
Azure HDInsight is a managed, open-source, analytics, and cloud-based service from Microsoft that provides customers broader analytics capabilities for big data - this helps organizations process large quantities of streaming or historical data. This article talks about Azure HDInsight, how to get started using it quickly, its use cases, how Big Data Analytics on Microsoft Azure works, and the best practices to follow when using Azure HDInsight.
Read more: Best practices to follow when using Azure HDInsights for Big Data & Analytics.
Azure Data Lake Pricing Explained
Azure Data Lake Storage Gen2 lets you run big data analytics lakes on top of Azure Blob Storage. Its pricing model is tied closely to Azure Blob Storage pricing. Understand key components of Azure Data Lake Gen2 pricing - data storage, transaction and data retrieval costs, archive tiers, and analytics charges.
Read more: Azure Data Lake Pricing Explained
Azure Data Box Gateway: Benefits, Use Cases, and 6 Best Practices
Azure Data Box Gateway is a cloud storage solution offered by Microsoft Azure that allows customers to move large amounts of data from on-premises to Azure cloud storage in a faster, more efficient, and secure manner. It is designed to simplify data migration, backup, and archival processes and is suitable for various use cases, including hybrid cloud and edge computing.
Read more: Azure Data Box Gateway: Benefits, Use Cases, and 6 Best Practices
Azure Data Box: Solution Overview and Best Practices
Azure Data Box is a physical data transfer device offered by Microsoft Azure. It is designed to help users securely move large volumes of data into and out of Azure. Data can be transferred using the device's high-speed network connections, and it also features security measures such as encryption and tracking.
Read more: Azure Data Box: Solution Overview and Best Practices
See Additional Guides on Key Managed Services Topics
Together with our content partners, we have authored in-depth guides on several other topics that can also be useful as you explore the world of managed services.
AWS Database
Authored by NetApp
- Types of Database Services Offered on AWS
- AWS Database as a Service: 8 Ways to Manage DBs in AWS
- Database Case Studies with Cloud Volumes ONTAP
Dedicated Server Hosting
Authored by Atlantic
- USA Dedicated Server Hosting & Dedicated Hosting
- Dedicated Servers | View Customizable Dedicated Server Plans
- Dedicated Hosts | Flexible Dedicated Cloud Hosts
Software Supply Chain
Authored by Mend
- Software Supply Chain Attacks
- What is the NIST Supply Chain Risk Management Program?
- A Guide To Implementing Software Supply Chain Risk Management
