Share
One of the main reasons for the growing adoption of AWS and other public clouds is the scale and the flexibility that the cloud offers. But in an environment where IT resources like Amazon EBS disks can be spun up on demand and start incurring costs immediately, how can you ensure your organization’s overall business costs, including those for AWS backup, don’t spiral out of control?
This article takes a deeper look at one way to achieve storage efficiency, and lower AWS total cost of ownership (TCO) by streamlining data from expensive Amazon EBS storage to inexpensive object storage platforms such as Amazon S3.
AWS Cloud Data Lifecycle
Whether using a traditional data center, a cloud platform like AWS, or some combination of both, data is the most important asset any organization has today.
All data typically goes through a data lifecycle, which starts when the data is generated, and continues as that data is processed, stored, consumed, archived, and, finally, retired or deleted. Let's take a closer look at each step of this process.
1. Data generation: During this stage, data is created either from within the AWS cloud platform or ingested from external sources such as a customer data center (as a part of AWS migration). Examples include creating new AWS EC2 compute instances with data volumes, typically stored on Amazon Elastic Block Storage (AWS EBS) or a customer uploading various backup data from their data center to an AWS S3 storage bucket for long term storage.
2. Data processing: During this stage, data gets staged (performing housekeeping tasks on data before they are ready for users / applications to consume) and cleansed (detect and remove inaccuracies). Thereafter, the data is analyzed and consumed. Examples include using AWS S3 or Amazon RDS for data staging, AWS Lambda or EMR for cleansing, and AWS Athena or Lambda or EC2 for analytics/consumption.
3. Data Archiving: During this stage, the active use of data is somewhat complete and is now stored for infrequent access and in keeping with long-term retention requirements. Examples include storing EBS backup data destined for long-term retention on Amazon S3 infrequent access storage classes or even deeper storage on Glacier or Glacier Deep Archive.
4. Data purging: During this stage, data that is no longer needed to be retained is typically retired and permanently deleted in order to free up storage capacity and reduce costs.
All data that traverses through these lifecycle stages can be categorized as hot, warm, or cold, based on its frequency of access. Typically, most data that belong to the data generation and data processing stages can be classed as hot or warm. Hot data tends to be freshly created or freshly ingested, and as such is accessed frequently for processing purposes. It therefore needs to be stored on a fast, highly performant storage platform such as an SSD-backed Amazon EBS volume, which of course has a premium cost associated with it.
However, once the data has been staged, a subset of that data may fall under the warm data category, such as unstructured files or replicated disaster recovery (DR) copy of a production workload from a private data center will not have frequent access needs and can therefore reside on cheaper, less performant storage tiers such as EBS volumes backed by mechanical disks or even cheaper Amazon S3 storage. Cold data that typically belongs to the data archiving stage is rarely accessed and would be perfectly suited for low-performant, less-expensive storage platforms such as Amazon S3 IA (infrequent Access) or Glacier.
How to Streamline EBS Data to Amazon S3
AWS EBS is the default block storage solution available for all AWS EC2 computing requirements. All primary block storage requirements—such as the system drive of an EC2 VM and the data and log drives for high-throughput applications like SQL or Oracle—will typically be stored on an EBS volume that is attached to an EC2 instance.
There are five different types of EBS volumes available, from slow-performant Magnetic type to high performance, throughput-optimized Provisioned IOPS disks based on SSD, with several intermediary options in between. Data stored within an EBS volume is persistent independently from the state of the Amazon EC2 instances. However, it is not automatically backed up by AWS.
Amazon EBS data is automatically replicated within the same Availability Zone (AZ) for data center redundancy. However, it is not automatically replicated across AZ’s or to other regions for Disaster Recovery (DR) purposes.
AWS users are responsible under the AWS shared ownership responsibility model to ensure adequate backup and DR is made available based on their specific business requirements. Many enterprise customers would expect typical enterprise data protection strategies such as the 3-2-1 strategy, as well as properly implemented multi-region AWS disaster recovery strategy.
While EBS offers excellent high-performance storage, it’s not the only storage option on AWS. Amazon S3 (Simple Storage Service) is a highly available, scalable, internet-based object storage platform designed for internet data. S3 data is stored on storage buckets and is accessed through a HTTP/S web interface. However, AWS doesn’t have a functionality to tier data between these two services. The only thing that comes close is EBS snapshots, which give AWS users the ability to bring the S3 storage features and benefits to streamline EBS data management in two key ways.
How to Streamline Backups
Upon the creation of an EBS snapshot, the data stored within the EBS volume(s) is automatically transferred to an Amazon S3 bucket for long-term storage purposes. This provides an easy-to-use, cost-efficient storage option for EBS backup data.
What kind of savings does this produce? As an example, EBS snapshots cost $0.05 per GB per month in the US-East region in comparison to $0.125 per GB per month for EBS Provisioned IOPS type which represents a huge cost savings to customers. Outside of this fixed snapshot costs, customers do not have to pay for any data egress charges or any additional S3 storage costs when leveraging EBS snapshots to streamline their data protection requirements.
Creating an EBS snapshot can be done via both the AWS management console as well as the command line using the create-snapshot AWS CLI command or the New-EC2Snapshot Powershell command). EBS snapshot lifecycle can also be managed through the use of Amazon Data Lifecycle Manager.
Here is how to do it using the management console.
1. On the EC2 dashboard window, click on “Volumes” under “ELASTIC BLOCK STORAGE” in the navigation pane on the left.
2. Select the EBS volume you would like to backup to S3 using an AWS snapshot.
3. Go to the “Actions” button on the menu bar and select “Create Snapshot” from the drop-down menu, as shown here:
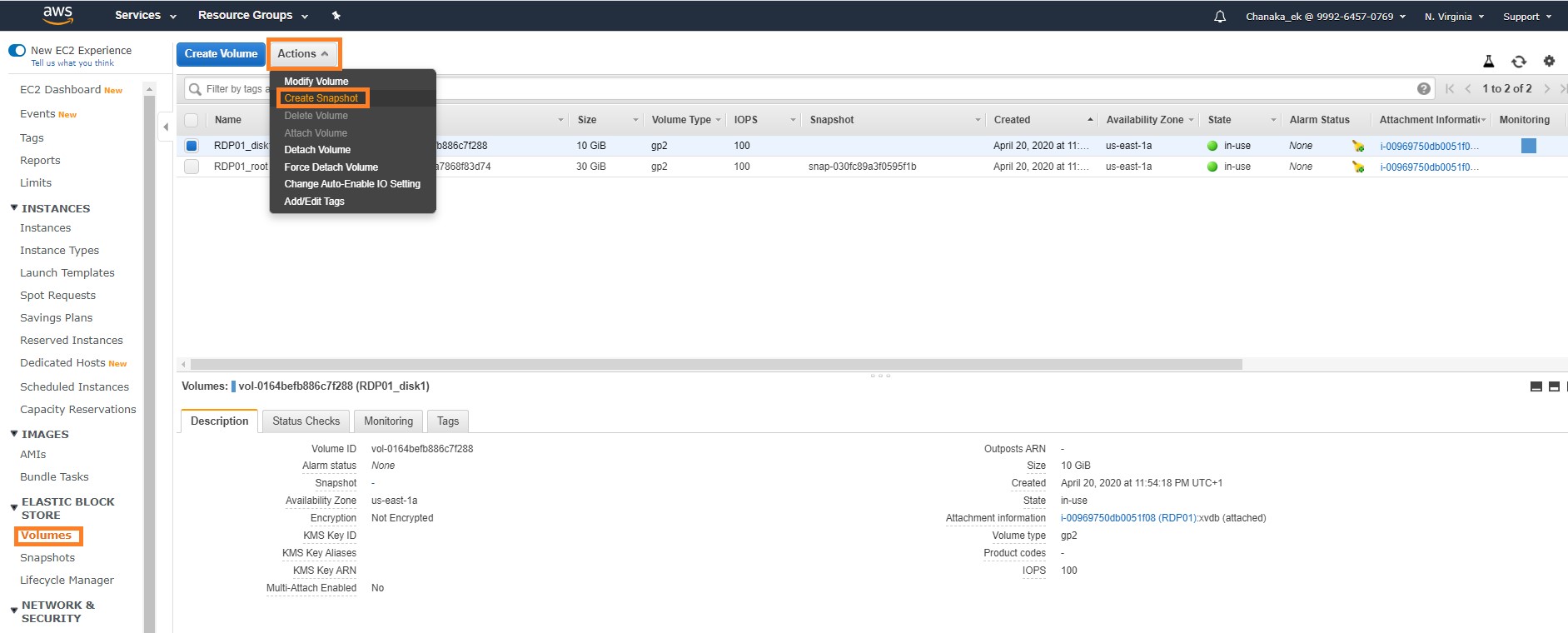
4. Provide a description for the snapshot and click “Create Snapshot”:
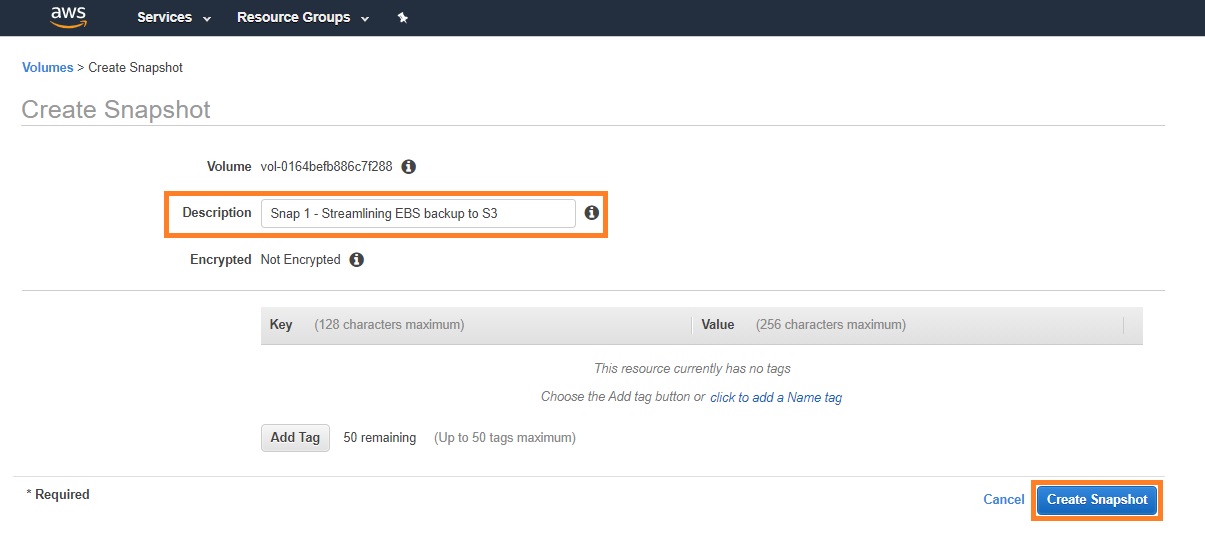
5. Once created, you can go to the “Snapshots” section on the navigation pane on the left and view the snapshots created:
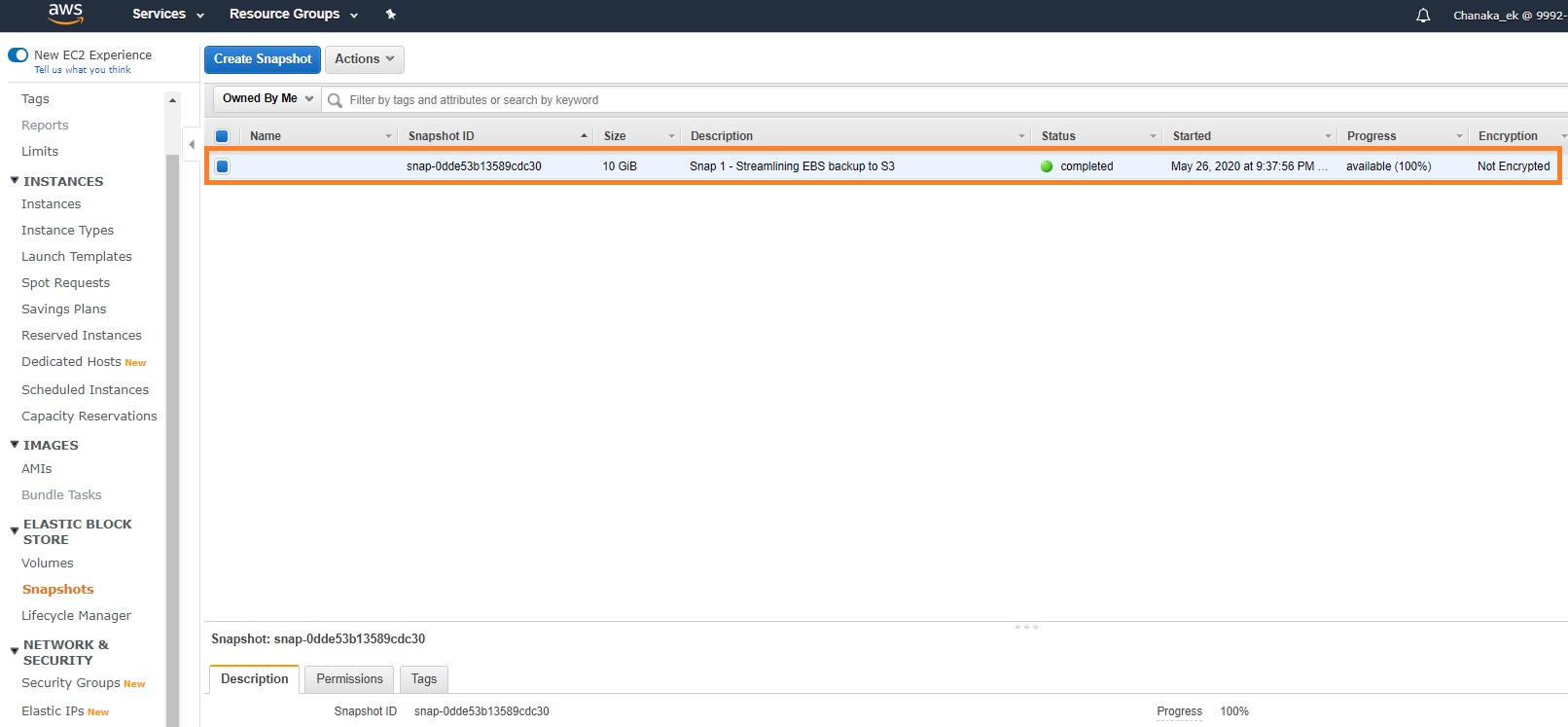
It should be noted that creation of an AWS snapshot will involve copying the entire dataset from EBS to S3, which can be a time-consuming task. If multiple snapshot copies are taken at the same time, this can cause a performance bottleneck on the underlying EBS volume.
Furthermore, AWS snapshots are crash consistent only, which means any specialist applications such as SQL or Oracle backups made via AWS snapshots may risk not being usable during a recovery scenario, unless the attached instance was switched off during the snapshot creation process to ensure the data consistency on disk. For enterprise databases, that won’t be feasible.
It is also important to note that the EBS snapshots are by default stored on a separate, AWS-managed S3 platform that is not the same as the ordinary S3 platform accessible to AWS users. This backend S3 platform used for AWS snapshots cannot be directly accessed by the end users in any shape or form. AWS users can only access EBS snapshot data stored on this hidden S3 platform via the “Snapshots” page on the AWS console as shown above, or via the command line.
Restoring Data from an EBS Snapshot
Restoring data from an EBS snapshot involves creating a new EBS volume from the base snapshot rather than doing an in-place restore, directly into the original EBS volume.
For example, the screenshot below illustrates how to create a new EBS volume using a pre created snapshot.
1. From the EC2 service dashboard, select the “Snapshots” link on the navigation pane on the left
2. Select a Snapshot created previously
3. Click “Actions” and then “Create a volume”
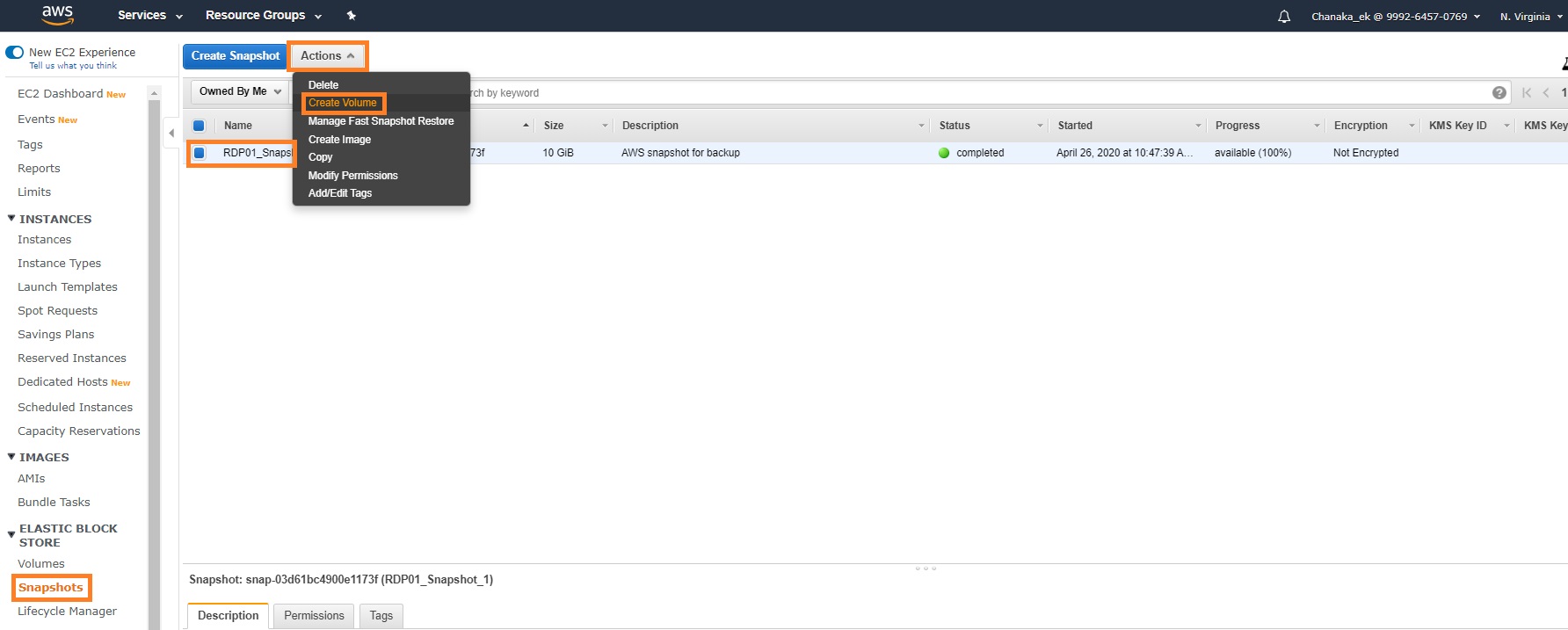
4. Follow the normal EC2 storage volume creation wizard steps that appear afterwards to complete the volume creation process.
While the creation of the new EBS volume is instantaneous, the actual data is lazy loaded: streamed as a background operation from the source EBS snapshot on S3 to the new EBS, a process volume which can take time. During this process, accessing data from the restored volume can have a significant performance impact (unless Fast Snapshot Restore [FSR] is used, which comes at an additional cost).
For those enterprise customers who may want to utilize the standard, user-accessible S3 storage buckets for storing their EBS backup data, there are solutions such as NetApp Cloud Volumes ONTAP’s data tiering, which can be used to turn EBS and S3 into AWS storage tiers.
How to Streamline for Availability
While all data stored on EBS is considered to be highly resilient (due to AWS maintaining multiple copies across multiple data centers), the data will only be available within a single AWS AZ by default. Data stored within AWS S3 however, are highly available across various AZs within a single Region. Using AWS snapshots to create copies of EBS data volumes therefore automatically increases the availability of EBS data beyond just a single AZ within a Region without the users having to action anything.
Furthermore, EBS snapshots can also be copied across multiple Regions, which substantially increases the availability of EBS data. That can be important for many enterprises that need to meet regulatory requirements when it comes to their AWS Disaster Recovery plans.
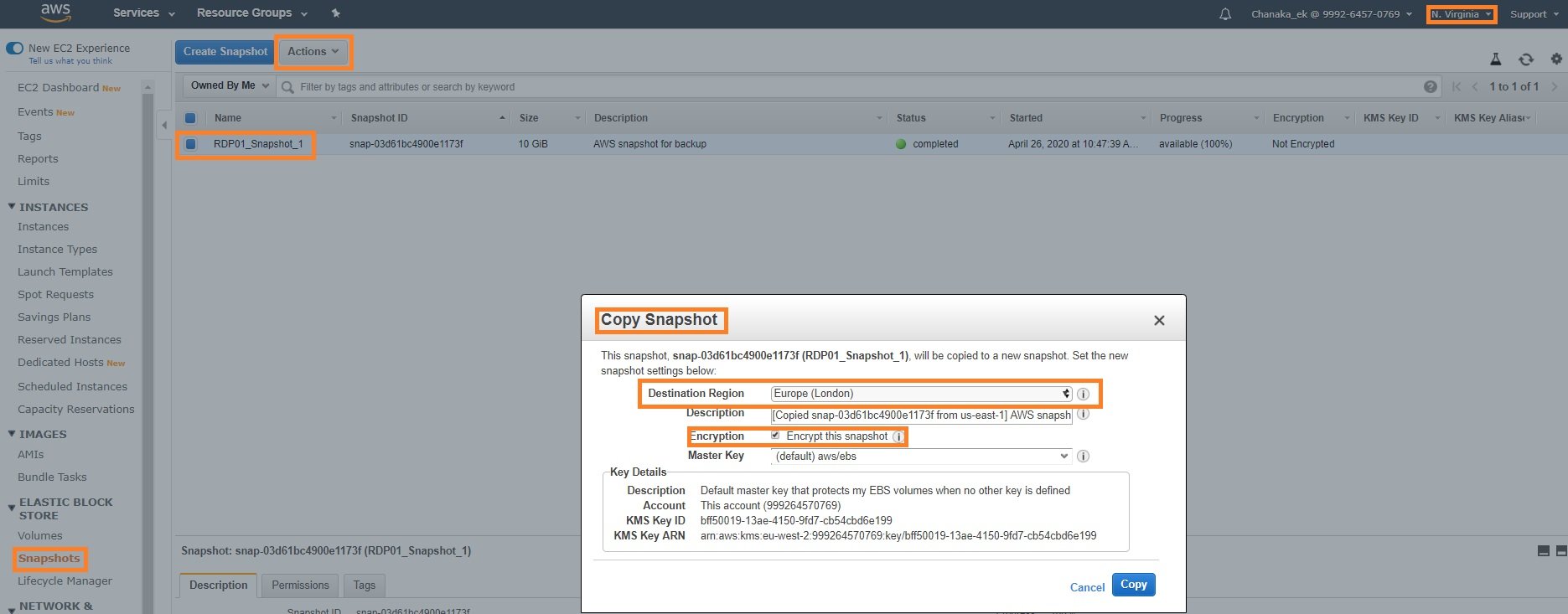
Here is how to copy data across AWS regions using snapshots:
1. From the EC2 window, select the “Snapshots” link on the navigation pane on the left.
2. Select the snapshot previously created. Click the “Actions” button and select “Copy” from the drop-down menu.
3. Complete the sections within the “Copy Snapshot” wizard as shown in the illustration below. Make sure to select a different AWS region as the destination region where the data will be copied.
Data center outages can happen, as do regional disasters. A credible DR plan should always ensure the cross regional availability of the business-critical data to overcome such incidents.
For those enterprises that may demand a more seamless, fully automated & A proven enterprise Disaster Recovery solution on AWS, NetApp Cloud Volumes ONTAP can provide a perfect DR solution.
Beyond Streamlining
Categorization of data based on the lifecycle stages and utilizing the appropriate storage tiers is essential to reducing the long-term AWS total cost of ownership for any customer. Identifying hot and cold data, based on the data lifecycle stages and then placing them on appropriate storage tiers is key to this. AWS snapshots enable customers to achieve this, while also increasing the data protection and data availability.
But the users should be aware of some of the key limitations such as slow snapshot creation time (due to delayed EBS to S3 copying), performance penalties during restores (due to lazy loading), and the inability to do in-place restores which can complicate or even prohibit customers from meeting certain requirements. These can be avoided by customers using NetApp Cloud Volumes ONTAP with built in NetApp Snapshot copies. NetApp Snapshots technology enables non-disruptive snapshot copies instantly to address data protection requirements without any performance penalties.
The built-in storage tiering feature allows Cloud Volumes ONTAP users to also benefit from streamlining not only snapshot data, but any cold data from Amazon EBS to Amazon S3 automatically. This process is ideal for data in the backup or archiving stage of the data lifecycle, which can help achieve considerable TCO savings. In addition, the built-in SnapMirror® technology enables Cloud Volumes ONTAP customers to easily implement seamless, enterprise grade disaster recovery capabilities across AWS regions.

