Share
Imagine an application that requires 24x7 availability and can allow a maximum of 15 minutes of downtime. How would you back up a database hosted on AWS EBS to meet those required SLAs?
AWS snapshot automation for EBS volume back up is the key to meeting strict recovery objectives. Automating the backup process is ideal since creating multiple regularly scheduled snapshots can be too time consuming to carry out manually. There are a number of methods that can be used to automate the snapshot creation process. It can be done programmatically through the AWS API and the AWS CLI, or through the fully managed AWS Backup service. Since AWS Backup is a much easier process, it has largely eclipsed the usage of the API and CLI.
In this article, we will discuss why timely AWS EBS snapshots are so important for data recovery and give you a step-by-step walkthrough on how to create automated AWS snapshots using the AWS Backup service.
To get started right away, click the links below:
- Automated Backups to the Rescue
- How to Set Up an AWS Backup Plan for EBS Volumes
- Get More Backup Protection for EBS with Cloud Volumes ONTAP
Automated Backups to the Rescue
How do automated backups work in practice? Let’s consider an e-commerce website running on the public cloud. As an online business with sales taking place globally, the website runs 24x7 on an highly available infrastructure without tolerance for any downtime.
This is a perfect case in which automating the backup of the database instance would prevent the loss of data. Automated backups make sure you are prepared for any kind of outages or failure states, including disaster recovery scenarios.
For the recovery of an application, recovery time objective (RTO) and recovery point objective (RPO) are two very significant parameters. The recovery time objective (RTO) is the maximum outage that is allowed on your application. For applications with zero RTO, the SLA is zero downtime. Practically, this is a very tough situation, but to achieve even 99% of that result, the redundant copies of data and the highly available infrastructure must be able to guarantee almost zero downtime.
The recovery point objective (RPO) indicates the amount of data that will be lost in the event of a system failure.
For example, say there is an application set up to take EBS snapshots every four hours, and then that system goes down. The data stored in the EBS volume since its last EBS volume backup is not recoverable in this case. The RPO in this case is four hours.
The RPO and RTO are inversely proportional to the money spent on your infrastructure. If your RPO and RTO are low, you have to ensure that you have an appropriate backup and data recovery strategy in place.
One of the best ways to do this is to prepare a timely backup of the EBS of the EC2 instance to which that EBS is connected. The EBS snapshot is stored on Amazon Simple Storage Service (S3) and can be used later to recover the database instance.
There are a number of methods to automatically create EBS snapshots that can be used for recovery. Currently AWS Backup is the preferred solution. AWS Backup is a fully managed service that not only protects EBS volumes, but also offers backup capabilities for EC2 instances, Amazon RDS, Storage Gateway, DynamoDB, EFS, and Aurora.
Below, we will give an example of how you can create a scheduled snapshot of one or more EBS volumes using AWS Backup.
How to Set Up an AWS Backup Plan for EBS Volumes
In this section we’ll take a look at how to use AWS Backup to automatically create snapshots of EBS volumes. The following procedure demonstrates how to set up a backup plan, a rule, and a single resource to be backed up.
The only prerequisite for this example is that you should have an EBS volume ready and available to be backed up as a resource that you will connect to your backup plan.
- Log in to the AWS Management console and select the AWS Backup service.
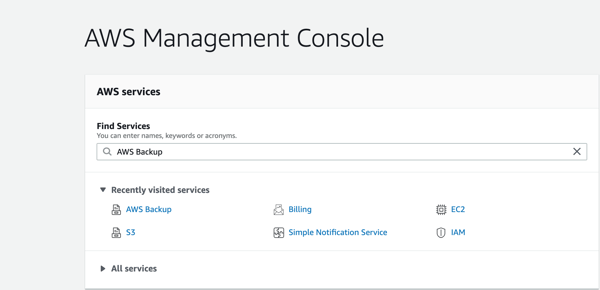
- In the dashboard, the choices are to “Manage Backup plans,” “Create an on-demand backup” and “Restore a backup.” Since we are going to create a backup plan, select “Manage Backup plans.”
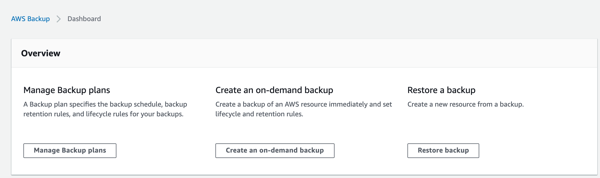
- In the Backup plans window, select “Create Backup plan” since we have no plans in place yet.
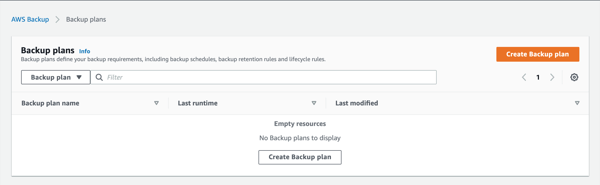
- In the “Create Backup plan” window, there are options to use a template, create a new plan from scratch, or define a plan using a JSON file. Since this is our first plan, we want to start off easy by using an existing template. Select “Start with a template.”
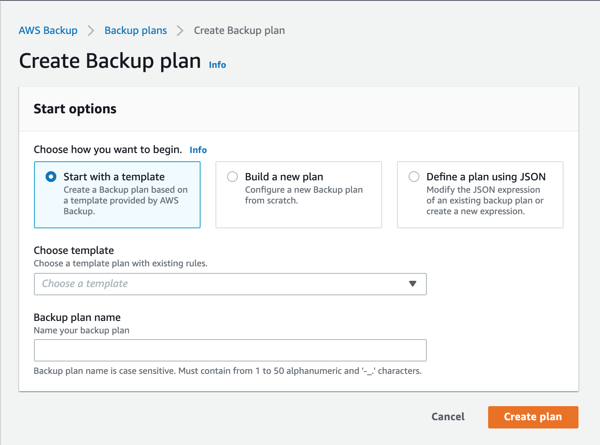
-
We click the “Choose template” bar and pick the very first template: Daily-35day-Retention. This means that one snapshot will be created every day and each of those snapshots are kept for 35 days before being deleted.
In the “Backup plan name,” enter a name for your plan. In this example we used “testplan.”
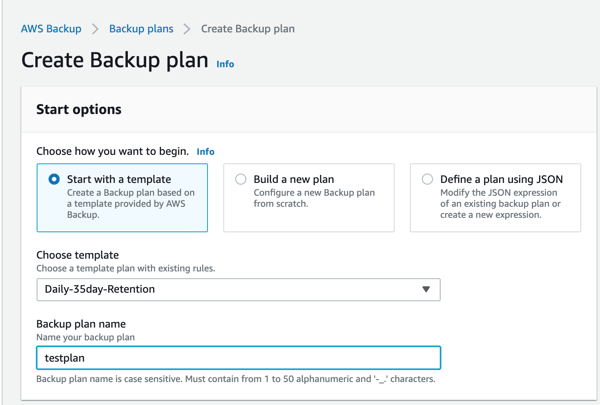
- Now scroll down a little bit and select “DailyBackups” as the backup rule. Click “Create Plan” at the bottom of the page.
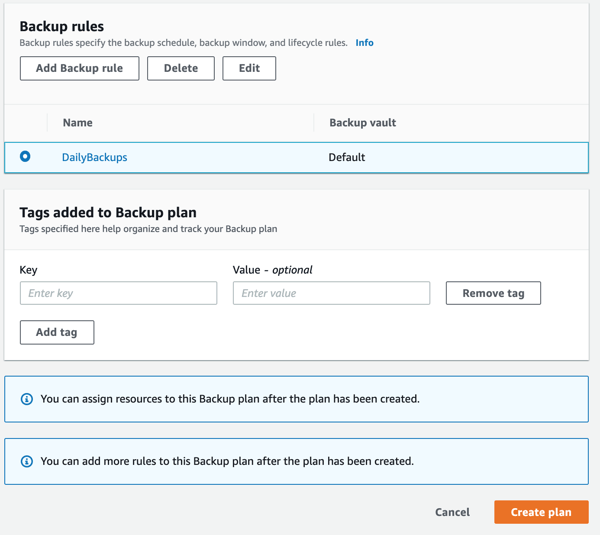
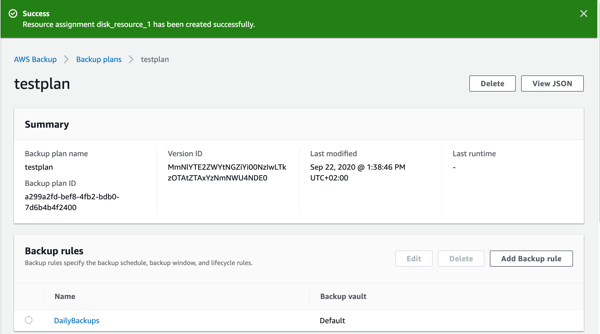
- Your backup plan will now be created. Next, you can add resources to the plan. Click “Assign resources” in the top right hand corner.
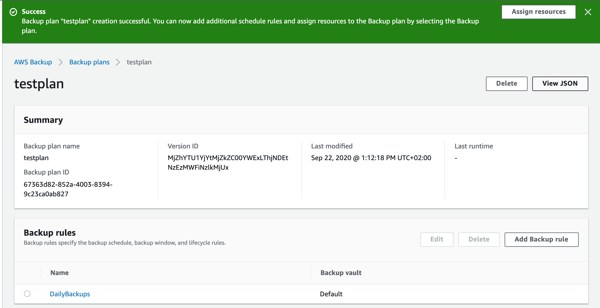
- On the Assign Resources screen, give the resource assignment a name. In the “assign by” pull down menu, select “resource-id.”
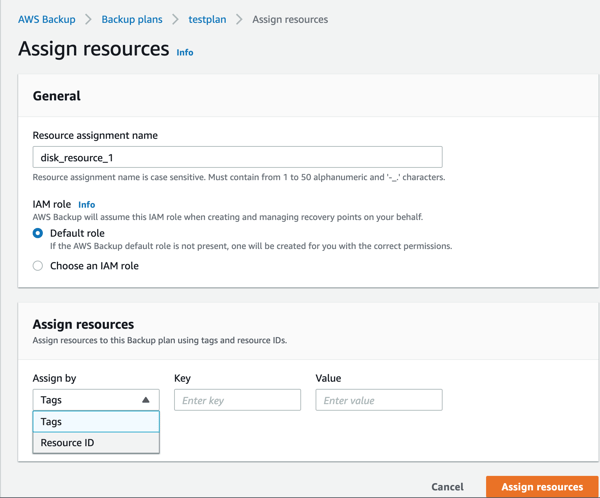
- For resource type, select EBS. For value, select your one and only volume. To continue, click the “Assign resources” button.
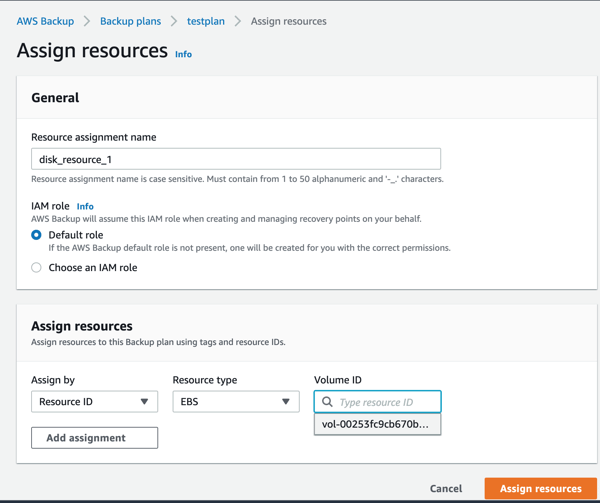
- You’ll now see that the resource has been added to the plan.
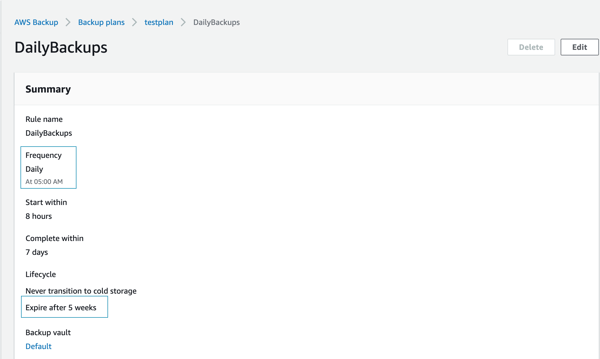
- For the final step, click on the “DailyBackups” rule once more and see the list summary of the rule you created. You’ll see that we are going to create a snapshot every day at 5:00 AM, and keep every snapshot for 5 weeks.
Get More Backup Protection for EBS with Cloud Volumes ONTAP
Now that you’ve seen how to create and automate your AWS EBS snapshot copies, you need to consider how those snapshots will be stored in the future. Amazon EBS snapshots are stored on Amazon S3, where costs are lower, but that storage service can’t be accessed as other data that is stored in Amazon S3 buckets. This can be somewhat limiting for a user who may want to gain access to those snapshots. The snapshots are also created without any storage efficiency, which means the copies take up storage space that AWS will sell to you for a charge.
Cloud Volumes ONTAP offers enhanced data protection capabilities that can address these concerns. First and foremost, NetApp Snapshot technology offers a faster, more space-efficient backup for Amazon EBS volume data. Plus, automatic data storage tiering allows you to tier snapshot and other infrequently used data between Amazon EBS and less-expensive Amazon S3 as determined by the data’s usage pattern. Cloud Volumes ONTAP also has powerful storage efficiencies that can lower your overall cloud data storage costs, and FlexClone® data cloning to create instant, zero-cost, writable data clones from snapshots, leveraging backups for dev/test purposes.

