Share
In this article, we’ll explain the concept of high availability and how to measure availability for IT systems. We’ll show how AWS can help you achieve high availability for cloud workloads, across compute, SQL databases and storage services.
Read on to learn how Amazon’s Infrastructure as a Service (IaaS) capabilities such as elastic load balancing, availability zones and auto-scaling can help you achieve high availability for enterprise workloads. In this blog post, we’ll also examine how NetApp Cloud Volumes ONTAP can help to achieve highly available storage in AWS.
This is part of an extensive series of guides about FinOps.
In this article, you will learn:
- What is high availability?
- High availability in AWS compute, databases and storage
- AWS high availability for EC2 instances
- AWS high availability for SQL databases on Amazon RDS
- AWS high availability for storage services
- Achieve AWS high availability with Cloud Volumes ONTAP
What Is High Availability?
Highly available systems are reliable in the sense that they continue operating even when critical components fail. They are also resilient, meaning that they are able to simply handle failure without service disruption or data loss, and seamlessly recover from such failure.
High availability is commonly measured as a percentage of uptime. The number of “nines” is commonly used to indicate the degree of high availability. For example, “four nines” is indicative of a system that is up 99.99% of the time, meaning it is down for only 52.6 minutes during an entire year.
The following elements help you implement highly available systems:
- Redundancy—ensuring that critical system components have another identical component with the same data, that can take over in case of failure.
- Monitoring—identifying problems in production systems that may disrupt or degrade service.
- Failover—the ability to switch from an active system component to a redundant component in case of failure, imminent failure, degraded performance or functionality.
- Failback—the ability to switch back from a redundant component to the primary active component, when it has recovered from failure.
AWS High Availability: Compute, Databases and Storage
AWS helps you achieve high availability for cloud workloads, across three different dimensions:
- Compute—Amazon EC2 and other services that let you provision computing resources, provide high availability features such as load balancing, auto-scaling and provisioning across Amazon Availability Zones (AZ), representing isolated parts of an Amazon data center.
- SQL databases—Amazon RDS and other managed SQL databases provide options for automatically deploying databases with a standby replica in a different AZ.
- Storage services—Amazon storage services, such as S3, EFS and EBS, provide built-in high availability options. S3 and EFS automatically store data across different AZs, while EBS enables deployment of snapshots to different AZs.
AWS High Availability for EC2 Instances
If you are running instances on Amazon EC2, Amazon provides several built-in capabilities to achieve high availability:
- Elastic Load Balancing—you can launch several EC2 instances and distribute traffic between them.
- Availability Zones—you can place instances in different AZs.
- Auto Scaling—use auto-scaling to detect when loads increase, and then dynamically add more instances.
These capabilities are illustrated in the diagram below. The Elastic Load Balancer distributes traffic between two or more EC2 instances, each of which can potentially be deployed in a separate subnet that resides in a separate Amazon Availability Zone. These instances can be part of an Auto-Scaling Group, with additional instances launched on demand.
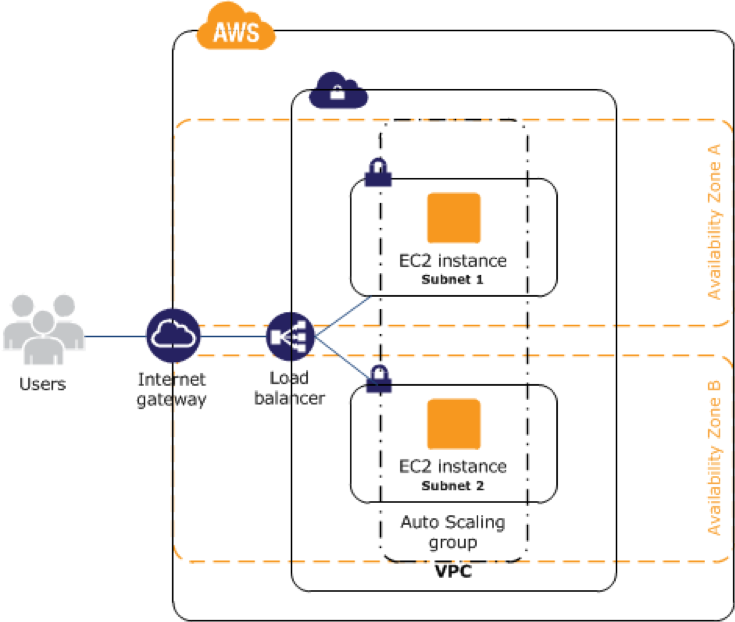
AWS High Availability for SQL Databases on Amazon RDS
If you are running an SQL database as part of your AWS application, you are probably running it using Amazon RDS.
RDS provides high availability using Multi-Availability Zone (Multi-AZ) deployments. This means RDS automatically provisions a synchronous replica of the database in a different availability zone. When the main database instance goes down, users are redirected transparently to the other availability zone.
This provides two levels of redundancy:
- In case the active database fails, there is a standby replica ready to receive requests
- In case of a disruption in the AZ your main database instance is running in, there is failover to another AZ.
The following diagram illustrates Multi-AZ database deployment.
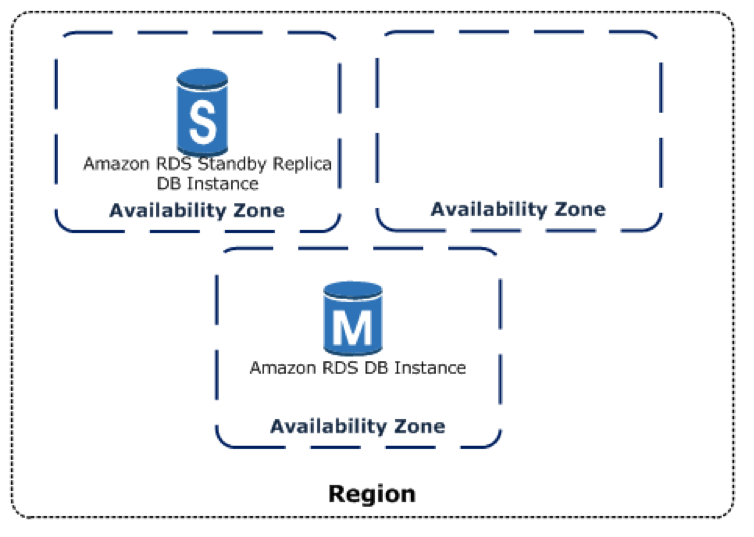
Source: Amazon Web Services
You can turn on this capability by specifying ‘Multi-AZ Deployment’ when creating an RDS database instance, either via the RDS Console or the Amazon CLI. Multi-AZ deployments are managed fully automatically, with no administrative intervention.
Note that Multi-AZ deployment is not supported for read-only instances, and you should use read replicas to enable high availability for those instances.
RDS provides the following capabilities per database type:
- For Oracle, PostgreSQL, MySQL, and MariaDB—high availability using Amazon Multi-AZ technology.
- For SQL Server—mirroring to another Availability Zone using Microsoft’s SQL Server Database Mirroring technology.
AWS High Availability for Storage Services
Here is a brief summary of the high availability capabilities Amazon offers for other popular storage services:
Amazon S3
S3 guarantees 99.999999999% (twelve 9’s) durability, by redundantly storing objects on multiple devices across a minimum of three AZs in an Amazon S3 Region.
Amazon EFS
EFS guarantees 99.9% availability, otherwise between 10-100% of the service fee is discounted. Every file system object is redundantly stored across multiple AZs.
Amazon EBS
EBS volumes are created in a specific AZ. You can make a volume available in another AZ and it can then be attached to other instances in that same Availability Zone. To make a volume available outside the AZ, or to create redundancy, you can create a snapshot and restore it in another AZ within the same region. You can also copy snapshots to other AWS regions, to create redundancy across Amazon data centers.
Achieve High Availability in AWS with Cloud Volumes ONTAP
NetApp Cloud Volumes ONTAP, the leading enterprise-grade storage management solution, delivers secure, proven storage management services on AWS, Azure and Google Cloud. The software-only service combines data control with enterprise-class storage features such as high availability, data protection, file share services, storage efficiencies, Kubernetes integration, and more.
In this blog post, we looked into the high availability capabilities of AWS storage services.
Using Cloud Volumes ONTAP, customers can leverage data protection and high availability, and operate non-disruptively while reducing the risks. Cloud Volumes ONTAP High Availability configuration will ensure business continuity with no data loss (RPO=0) and minimal recovery times (RTO < 60 secs).
Cloud Volumes ONTAP high availability ensures your applications run smoothly 24/7. Through its dual-node configuration with synchronous replication, the solution provides 100% data integrity, enabling zero RPO and reduction of RTO below 60 seconds.
Want to learn more about AWS high availability? Read our articles:
AWS Availability Zones, Regions, & Placement Groups Explained
Business organizations make use of applications that require different levels of availability and different SLA objectives. Learn how AWS Availability Zones, regions, multi-AZ deployments, and placement groups can help you improve availability and resilience for your workloads.
Read AWS Availability Zones, Regions, & Placement Groups Explained to learn more.
AWS GovCloud Services: Sensitive and Classified Data on the Public Cloud
AWS GovCloud is a separate AWS Region aimed for the use of USA government agencies, organizations working with the United States government, or projects that need to adhere to stringent standards or regulations. GovCloud helps users move sensitive workloads to the Amazon cloud, while adhering to their specific regulatory and compliance requirements.
In addition to its special security and access capabilities, GovCloud is a regular Amazon region that provides all the basic Amazon services.
Learn how AWS GovCloud services provide enhanced security for sensitive and classified data used by US government agencies and their partners and vendors.
Read more: AWS GovCloud Services: Sensitive and Classified Data on the Public Cloud
High Availability Cluster: Concepts and Architecture
High availability clusters provide continuous availability. Learn how high availability clusters work, what concepts you should understand before adoption, and what are the most important requirements.
Read more: High Availability Cluster: Concepts and Architecture
Creating high availability systems in AWS
Mission-critical systems require a recovery point objective (RPO) of 0. Both cloud and on-premise storage solutions need to ensure no data is lost when an outage occurs. There are many solutions that can help you create highly available systems in the cloud. However, choosing and coordinating these services is challenging.
Read How to Create High Availability Systems in AWS to Reach RPO 0 to learn about AWS high availability services and how they compare with Cloud Volumes ONTAP HA.
Data redundant sites
Even after moving your workloads to AWS, the shared responsibility model states that you are responsible for some portions of your stored data. This means you need to ensure your secondary site has redundancy for data storage. Cloud Volumes ONTAP can help you deal with the challenges of creating data redundant sites in AWS.
Cloud Volumes ONTAP allows you to easily create secondary copies of your on-premises deployments, and make sure that if one site fails, you can failover and failback between copies with no data loss.
Read Data Redundancy with AWS and Cloud Volumes ONTAP to learn more.
AWS high availability architecture
AWS has a global infrastructure to provide high availability for cloud workloads. The key components of this architecture include:
- Regions—21 geographical zones each containing at least three availability zones.
- Availability zones—66 global zones, which are self-sufficient data centers with redundant power, networking and cooling. Deploying across several AZs can protect your applications and provide you with resiliency in case failures occur.
- Compliance and data residency—Amazon provides full control over AWS regions to help you comply with data sovereignty requirements.
Read Making the Most of AWS High Availability Architecture for Enterprise Workloads to learn more about availability zones, including best practices for AWS high availability.
Setting Up Cloud Volumes ONTAP HA Configuration in Multiple Availability Zones
You can deploy Cloud Volumes ONTAP HA for AWS in multiple AWS Availability Zones, to ensure high availability in case a single availability zone fails.
Normally, Cloud Volumes ONTAP HA restricts access to one VPC. Read this guide to learn how to allow multiple VPCs to use the same Cloud Volumes ONTAP HA configuration.
AWS Data Loss Prevention (DLP)
DLP refers to tools and protocols used for protection against data loss or theft. Data loss can be caused by viruses and malware, power failures or insider threats. There are multiple approaches you can adopt to protect your data in AWS, all of which require security monitoring and a general understanding of security patterns.
Common DLP patterns in AWS include:
- Encrypting S3 data
- Monitoring S3 buckets
- Protecting S3-based data with policies
To learn more about DLP approaches and tools in AWS read AWS Data Loss Prevention: Tools and Strategies.
Maintaining Application Availability in the Cloud
Keeping applications up and running continuously is a major concern for enterprises. This requires not only taking steps to prevent downtime, but also recovering from failure as quickly as possible with minimal data loss. When relying solely on cloud service providers, enterprises struggle to reach near-zero recovery point objectives (RPO) and recovery time objectives (RTO). Attempting to meet these requirements with tools such as application layers, OS or databases often result in high costs, risks and complications.
Cloud Volumes ONTAP high availability ensures your applications run smoothly 24/7. Through its dual-node configuration with synchronous replication, the solution provides 100% data integrity, enabling zero RPO and reduction of RTO below 60 seconds.
Read Application Availability in the Cloud: Meeting the Challenges of High Availability and Continuous Operation to learn more.
Windows Server Failover Clustering on AWS with NetApp Cloud Volumes ONTAP
One way that companies can ensure high availability in their data centers is with Windows Server Failover Clustering, also known as WSFC. By providing a native HA platform through By using Active / Passive servers with shared access to the same storage, WSFC provides applications with assured uptime.
In this post we take an in-depth look at WSFC and its benefits for AWS HA when using Cloud Volumes ONTAP.
Read more in Windows Server Failover Clustering on AWS with NetApp Cloud Volumes ONTAP
See Additional Guides on Key FinOps Topics
Together with our content partners, we have authored in-depth guides on several other topics that can also be useful as you explore the world of FinOps.
AWS Cost Optimization
Authored by Spot
- AWS Cost Optimization Tools and Tips: Ultimate Guide
- AWS Pricing Calculator: Calculate AWS Cost Like the Pros
- AWS Cost Savings: 12 Great Ways to Save on AWS
AWS Pricing
Authored by Spot
- AWS Pricing: 5 Models & Pricing for 10 Popular AWS Services
- Fargate vs. EC2: What is the difference and which is best for ECS?
- Run an EMR Cluster on Spot Instances in 5 Steps
Azure Cost Optimization
Authored by Spot
- Azure Cost Management: 4 Ways to Optimize Azure Costs
- Azure Cost Analysis: Analyzing Azure Costs, Step by Step
- Azure Alerts: Basics, Alert Types and 4 Best Practices
